







苹果这项新工作将为未来 iPhone 加入大模型的能力带来无限想象力。
近年来,gpt-3、opt和palm等大型语言模型(llm)在广泛的自然语言处理(nlp)任务中展现了强大的性能。然而,这些性能的实现需要大量的计算和内存推理,因为这些大型语言模型可能包含数千亿甚至万亿个参数,这使得在资源有限的设备上高效加载和运行变得具有挑战性
当前标准的应对方案是将整个模型加载到 DRAM 中进行推理,然而这种做法严重限制了可以运行的最大模型尺寸。举个例子,70 亿参数的模型需要 14GB 以上的内存才能加载半精度浮点格式的参数,这超出了大多数边缘设备的能力。
为了解决这种局限性,苹果的研究者提出在闪存中存储模型参数,至少比 DRAM 大了一个数量级。接着在推理中,他们直接并巧妙地进行闪存加载所需参数,不再需要将整个模型拟合到 DRAM 中。
这种方法基于最近的工作构建,这些工作表明 LLM 在前馈网络(FFN)层中表现出高度稀疏性,其中 OPT、Falcon 等模型的稀疏性更是超过 90%。因此,研究者利用这种稀疏性, 有选择地仅从闪存中加载具有非零输入或预测具有非零输出的参数。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文地址:https://arxiv.org/pdf/2312.11514.pdf
具体来讲,研究者讨论了一种受硬件启发的成本模型,其中包括闪存、DRAM 和计算核心(CPU 或 GPU)。接着引入两种互补技术来最小化数据传输、最大化闪存吞吐量:
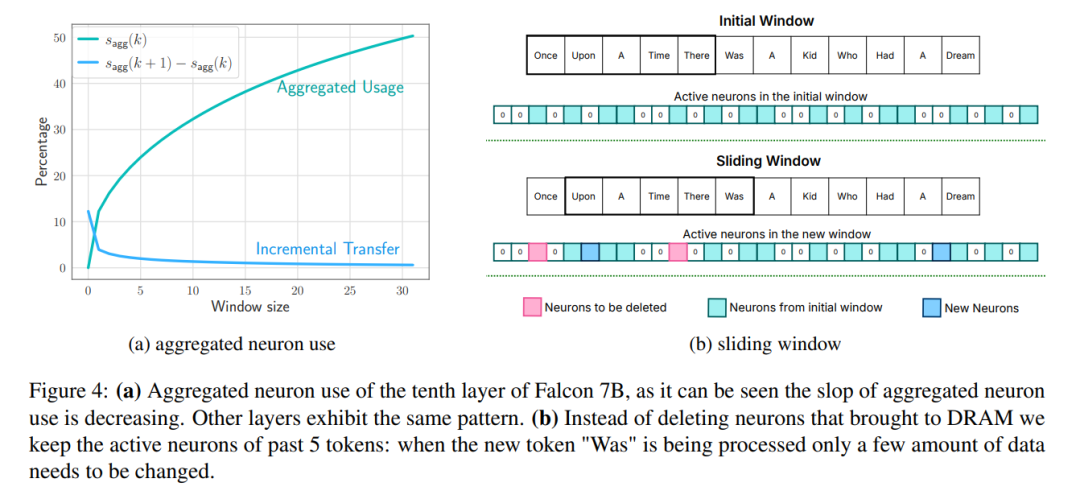
窗口:只加载前几个标记的参数,并重用最近计算的标记的激活。这种滑动窗口方法减少了加载权重的 IO 请求数量;
行列捆绑:存储上投影和下投影层的串联行和列,以读取闪存的更大连续块。这将通过读取更大的块来增加吞吐量。
为了进一步减少从闪存传输到DRAM的权重数量,研究人员尝试预测FFN的稀疏性并避免加载归零参数。通过结合使用窗口和稀疏性预测,每个推理查询仅需加载2%的闪存FFN层。他们还提出了静态内存预分配,以最大程度地减少DRAM内的传输并减少推理延迟
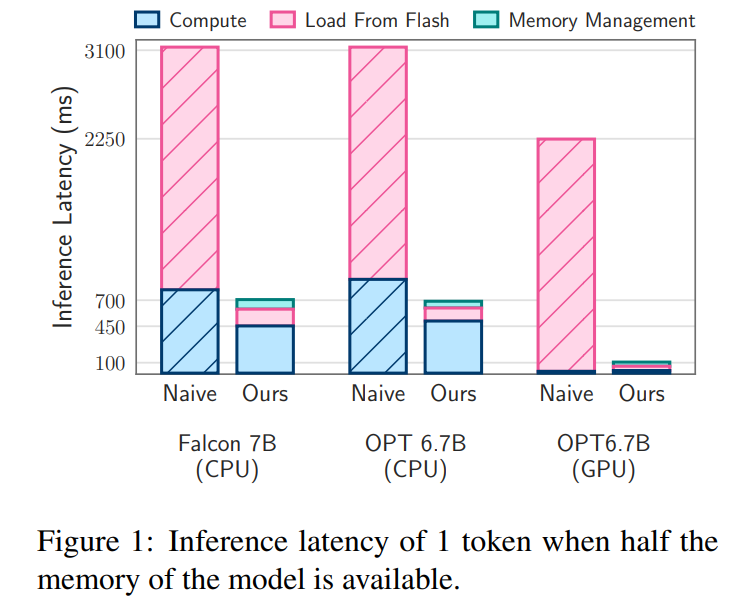
本文的闪存加载成本模型在加载更好数据与读取更大块之间取得了平衡。与 CPU 和 GPU 中的 naive 实现相比,优化该成本模型并有选择地按需加载参数的闪存策略可以运行两倍于 DRAM 容量的模型,并将推理速度分别提升 4-5 倍和 20-25 倍。
有人评价称,这项工作会让 iOS 开发更加有趣。
闪存和 LLM 推理
带宽和能量限制
虽然现代 NAND 闪存提供了高带宽和低延迟,但仍达不到 DRAM 的性能水准,尤其是在内存受限的系统中。下图 2a 说明了这些差异。
依赖 NAND 闪存的 naive 推理实现可能需要为每个前向传递重新加载整个模型,这一过程非常耗时,即使是压缩模型也需要几秒时间。此外将数据从 DRAM 传输到 CPU 或 GPU 内存需要耗费更多能量。
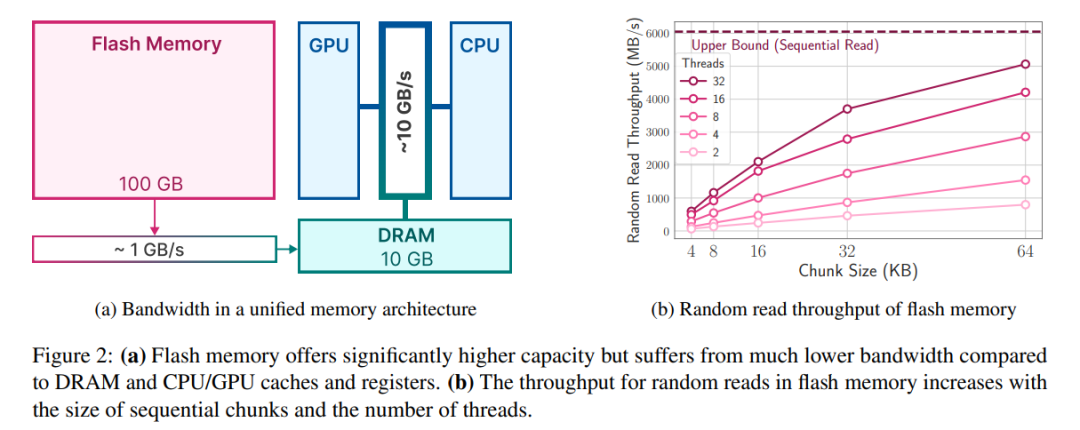
在 DRAM 充足的场景中,加载数据的成本有所降低,这时模型可以驻留在 DRAM 中。不过,模型的初始加载仍然耗能,尤其是在第一个 token 需要快速响应时间的情况下。本文的方法利用 LLM 中的激活稀疏性,通过有选择地读取模型权重来解决这些挑战,从而减少了时间和耗能成本。
重新表达为:获取数据传输速率
在大量连续读取的情况下,闪存系统表现最佳。举例来说,苹果MacBook Pro M2配备了2TB的闪存,在基准测试中,未缓存文件进行1GiB的线性读取速度超过了6GiB/s。然而,由于这些读取具有多阶段性质,包括操作系统、驱动程序、中端处理器和闪存控制器,较小的随机读取无法达到如此高的带宽。每个阶段都会带来延迟,从而对较小的读取速度造成较大的影响
为了规避这些限制,研究者提倡两种主要策略,它们可以同时使用。
第一种策略是读取较大的数据块。虽然吞吐量的增长不是线性的(较大的数据块需要较长的传输时间),但初始字节的延迟在总请求时间中所占的比例较小,从而提高了数据读取的效率。图 2b 描述了这一原理。一个与直觉相反但却有趣的观察结果是,在某些情况下,读取比需要更多的数据(但数据块较大)然后丢弃,比只读取需要的部分但数据块较小更快。
第二种策略是利用存储堆栈和闪存控制器固有的并行性来实现并行读取。研究结果表明,在标准硬件上使用多线程 32KiB 或更大的随机读取,可以实现适合稀疏 LLM 推理的吞吐量。
最大化吞吐量的关键在于权重的存储方式,因为提高平均块长度的布局可以显著提高带宽。在某些情况下,读取并随后丢弃多余的数据,而不是将数据分割成更小的、效率更低的数据块,可能是有益的。
进行闪存加载
受上述挑战的启发,研究者提出了优化数据传输量和提高重新表达为:获取数据传输速率的方法,以显著提高推理速度。本节将讨论在可用计算内存远远小于模型大小的设备上进行推理所面临的挑战。
分析该挑战,需要在闪存中存储完整的模型权重。研究者评估各种闪存加载策略的主要指标是延迟,延迟分为三个不同部分:进行闪存加载的 I/O 成本、管理新加载数据的内存开销以及推理操作的计算成本。

苹果将在内存限制条件下减少延迟的解决方案分为三个战略领域,每个领域都针对延迟的特定方面:
1、减少数据负载:旨在通过加载更少的数据来减少与闪存 I/O 操作相关的延迟。
2、优化数据块大小:通过增加加载数据块的大小来提高闪存吞吐量,从而减少延迟。
以下是研究者为提高闪存读取效率而增加数据块大小所采用的策略:
捆绑列和行
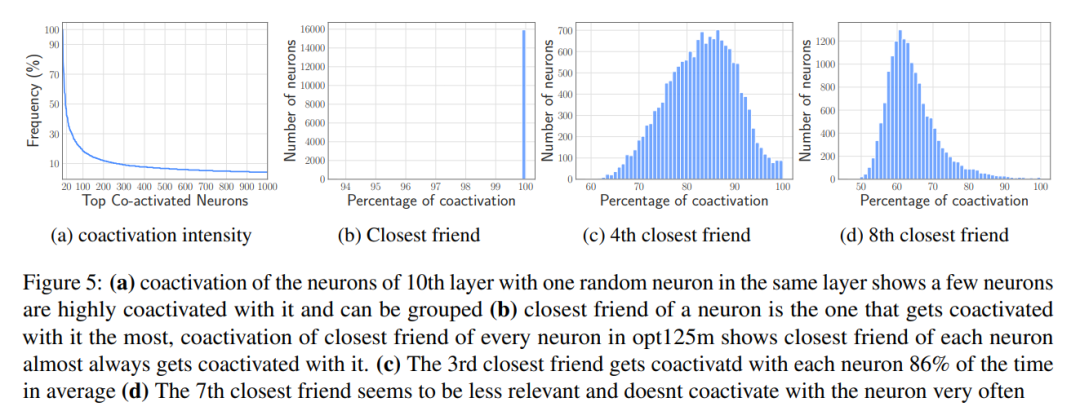
基于 Co-activation 的捆绑
3、有效管理加载的数据:简化数据加载到内存后的管理,最大限度地减少开销。
虽然与访问闪存相比,在 DRAM 中传输数据的效率更高,但会产生不可忽略的成本。在为新神经元引入数据时,由于需要重写 DRAM 中的现有神经元数据,重新分配矩阵和添加新矩阵可能会导致巨大的开销。当 DRAM 中的前馈网络(FFN)有很大一部分(约 25%)需要重写时,这种代价尤其高昂。
为了解决这个问题,研究者采用了另一种内存管理策略。这种策略包括预先分配所有必要的内存,并建立相应的数据结构来进行有效的管理。如图 6 所示,该数据结构包括指针、矩阵、偏移、已使用数和 last_k_active 等元素
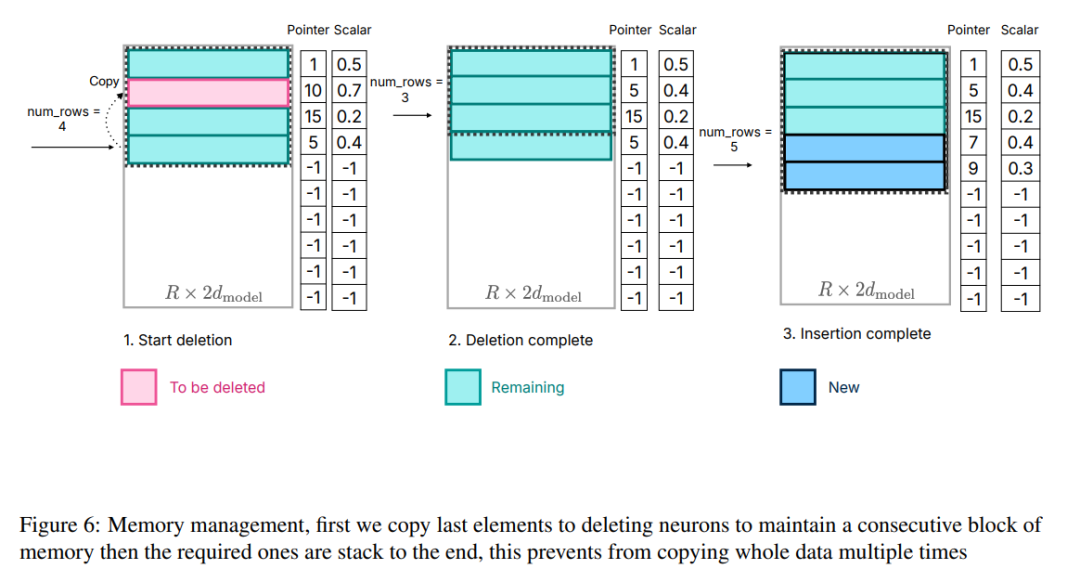
图 6:内存管理,首先将最后一个元素复制到删除神经元,以保持内存块的连续性,然后将所需元素堆栈到最后,这样可以避免多次复制整个数据。
需要注意的是,重点并不在于计算过程,因为这与本文的核心工作无关。这种划分使得研究者能够专注于优化闪存交互和内存管理,从而在内存有限的设备上实现高效的推理
需要进行实验结果的重写
OPT 6.7B 模型的结果
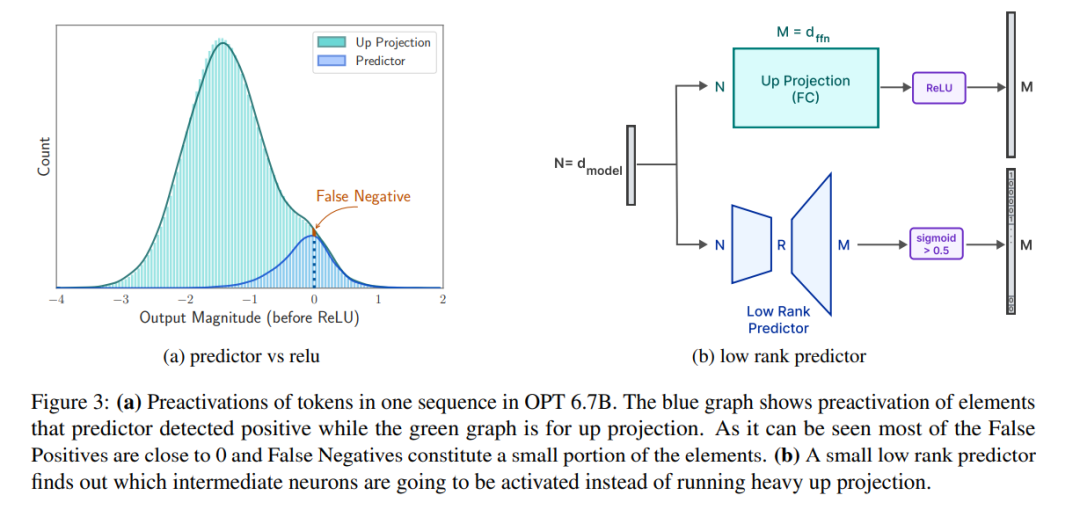
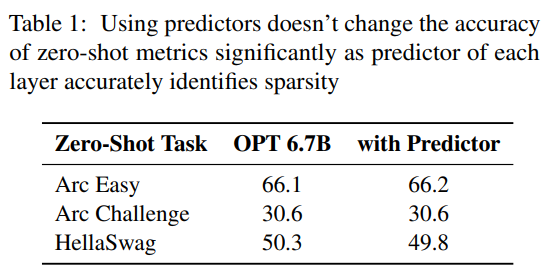
预测器。如图 3a 所示,本文的预测器能准确识别大多数激活的神经元,但偶尔也会误识数值接近于零的非激活神经元。值得注意的是,这些接近零值的假负类神经元被排除后,并不会明显改变最终输出结果。此外,如表 1 所示,这样的预测准确度水平并不会对模型在零样本任务中的表现产生不利影响。
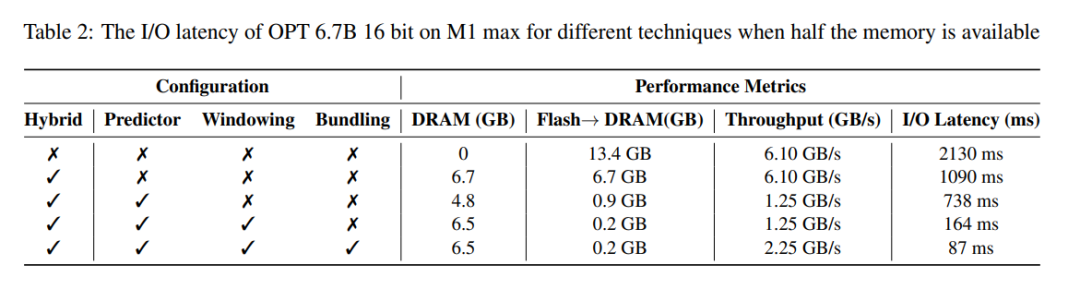
延迟分析。当窗口大小为 5 ,每个 token 需要访问 2.4% 的前馈网络(FFN)神经元。对于 32 位模型,每次读取的数据块大小为 2dmodel × 4 字节 = 32 KiB,因为它涉及行和列的连接。在 M1 Max 上,进行闪存加载每个 token 的延迟为 125 毫秒,内存管理(包括神经元的删除和添加)的延迟为 65 毫秒。因此,与内存相关的总延迟不到每个 token 190 毫秒(参见图 1)。相比之下,基线方法需要以 6.1GB/s 的速度加载 13.4GB 的数据,导致每个 token 的延迟约为 2330 毫秒。因此,与基线方法相比,本文的方法有了很大改进。
对于 GPU 机器上的 16 位模型,闪存加载时间缩短至 40.5 毫秒,内存管理时间为 40 毫秒,由于从 CPU 向 GPU 传输数据的额外开销,时间略有增加。尽管如此,基线方法的 I/O 时间仍然超过 2000 毫秒。
表 2 提供了每种方法对性能影响的详细比较。
Falcon 7B 模型的结果
延迟分析。在本文的模型中使用大小为 4 的窗口,每个 token 需要访问 3.1% 的前馈网络(FFN)神经元。在 32 位模型中,这相当于每次读取的数据块大小为 35.5 KiB(按 2dmodel ×4 字节计算)。在 M1 Max 设备上,进行闪存加载这些数据所需的时间约为 161 毫秒,内存管理过程又增加了 90 毫秒,因此每个 token 的总延迟时间为 250 毫秒。相比之下,基线延迟时间约为 2330 毫秒,本文的方法大约快 9 到 10 倍。





























