







随着gpt-3等大型语言模型的问世,自然语言处理(nlp)领域取得了重大突破。这些语言模型具备生成类人文本的能力,并已广泛应用于各种场景,如聊天机器人和翻译
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

然而,当涉及到专业化和定制化的应用场景时,通用的大语言模型可能在专业知识方面会有所不足。用专业的语料库对这些模型进行微调往往昂贵且耗时。“检索增强生成”(RAG)为专业化应用提供了一个新技术方案。
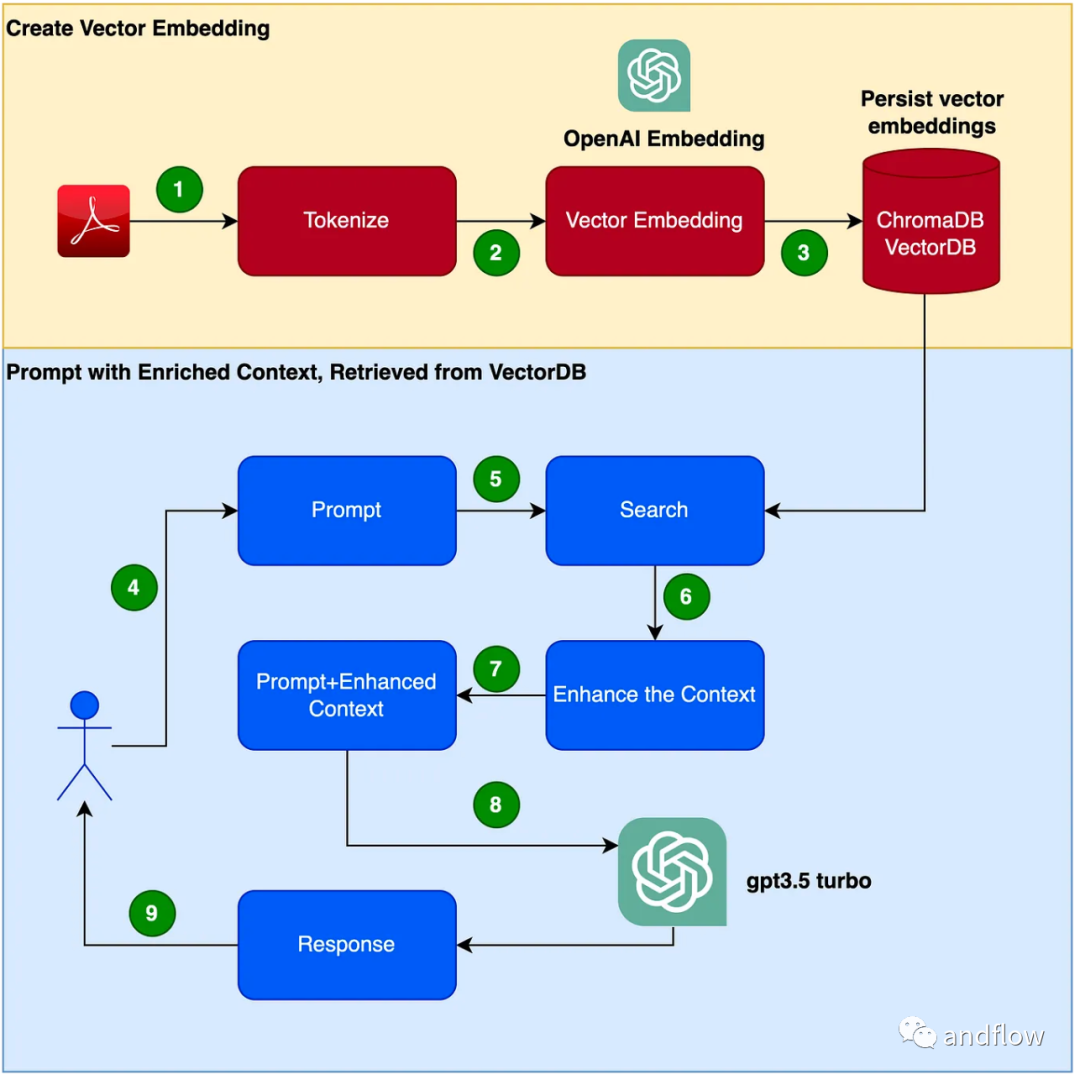
下面我们主要介绍RAG如何工作,并通过一个实际的例子,将产品手册作为专业语料库,使用GPT-3.5 Turbo来作为问答模型,验证其有效性。
案例:开发一个聊天机器人,能够回答与特定产品相关的问题。该企业拥有独特的用户手册
RAG介绍
RAG 提供了一种有效的解决方案,用于特定领域的问答。它主要通过将行业知识转化为向量进行存储和检索,并将检索结果与用户问题结合形成提示信息,最终利用大型模型生成合适的回答。通过结合检索机制和语言模型,大大增强了模型的响应能力
创建聊天机器人程序的步骤如下:
- 读取PDF(用户手册PDF文件)并使用chunk_size为1000个令牌进行令牌化。
- 创建向量(可以使用OpenAI EmbeddingsAPI来创建向量)。
- 在本地向量库中存储向量。我们将使用ChromaDB作为向量数据库(向量数据库也可以使用Pinecone或其他产品替代)。
- 用户发出具有查询/问题的提示。
- 根据用户的问题从向量数据库检索出知识上下文数据。这个知识上下文数据将在后续步骤中与提示词结合使用,来增强提示词,通常被称为上下文丰富。
- 提示词包含用户问题和增强的上下文知识一起被传递给LLM
- LLM 基于此上下文进行回答。
动手开发
(1)设置Python虚拟环境 设置一个虚拟环境来沙箱化我们的Python,以避免任何版本或依赖项冲突。执行以下命令以创建新的Python虚拟环境。
需要重写的内容是:pip安装virtualenv,python3 -m venv ./venv,source venv/bin/activate
需要进行改写的内容是:(2)生成OpenAI密钥
使用GPT需要一个OpenAI密钥来进行访问
需要进行重写的内容是:(3)安装依赖库
安装程序需要的各种依赖项。包括以下几个库:
- lanchain:一个开发LLM应用程序的框架。
- chromaDB:这是用于持久化向量嵌入的VectorDB。
- unstructured:用于预处理Word/PDF文档。
- tiktoken: Tokenizer framework
- pypdf:读取和处理PDF文档的框架。
- openai:访问OpenAI的框架。
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
创建一个环境变量来存储OpenAI密钥。

export OPENAI_API_KEY=
(4)将用户手册PDF文件转化为向量并将其存储在ChromaDB中
将所有需要使用的依赖库和函数导入
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
读取PDF,标记化文档并拆分文档。
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)创建一个chroma集合,和一个存储chroma数据的本地目录。然后,创建一个向量(embeddings)并将其存储在ChromaDB中。
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData,embeddings,collection_name=collection_name,persist_directory=persist_directory)vectDB.persist()执行此代码后,您应该看到一个已经创建好的文件夹,用于存储向量。
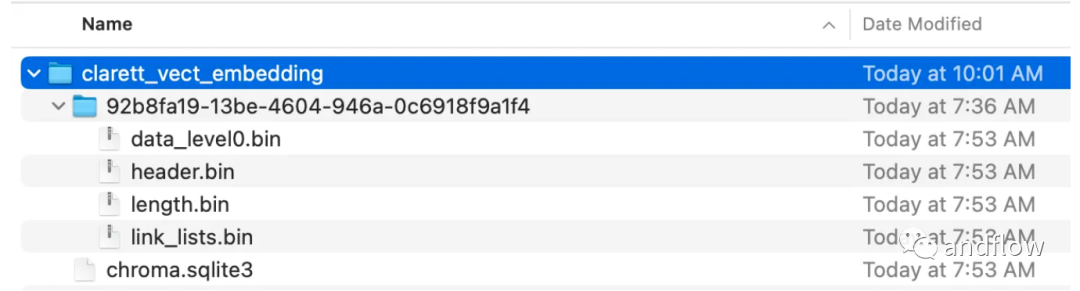
在将向量嵌入存储在ChromaDB后,可以使用LangChain中的ConversationalRetrievalChain API来启动一个聊天历史组件
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm(OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)
初始化了langchan之后,我们可以使用它来聊天/Q A。下面的代码中,接受用户输入的问题,并在用户输入'done'之后,将问题传递给LLM,以获得答复并打印出来。
chat_history = []qry = ""while qry != 'done':qry = input('Question: ')if qry != exit:response = chatQA({"question": qry, "chat_history": chat_history})print(response["answer"])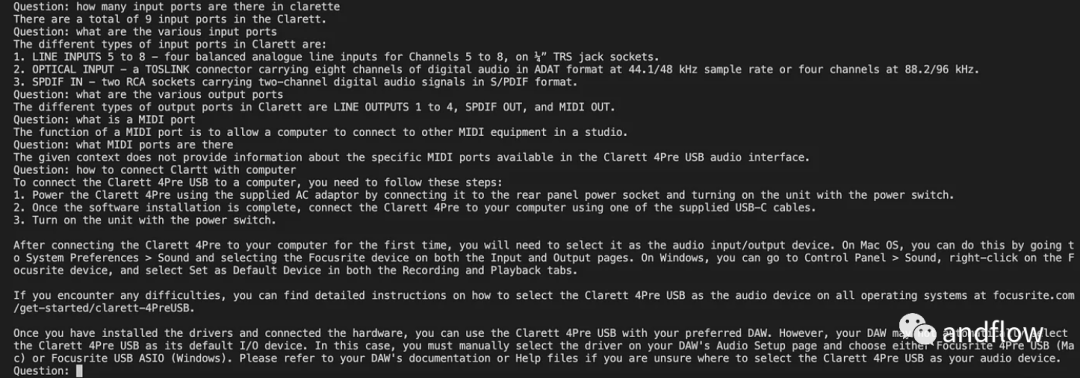

总之
RAG将GPT等语言模型的优势与信息检索的优势结合在一起。通过利用特定的知识上下文信息来增强提示词的丰富度,使得语言模型能够生成更准确、与知识上下文相关的回答。RAG提供了一种比“微调”更高效且成本效益更好的解决方案,为行业应用或企业应用提供可定制化的互动方案




























