







在当今数字化时代,pdf文件的应用极为普遍,其中所包含的图片与表格信息提取需求也不断上升。那么,如何高效地识别pdf中的图片和表格内容呢?
使用专业软件进行识别
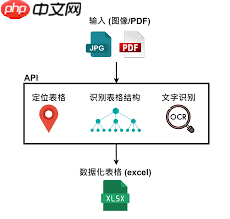
目前市场上有许多专用于处理PDF文档的工具,具备出色的图片与表格识别能力。例如Adobe Acrobat DC,不仅能够精准识别文本内容,还能对嵌入的图片和表格进行有效解析。借助该软件,用户可以方便地提取表格数据,并对图像内容进行基础分析。同时,福昕PDF阅读器在识别PDF中的图表方面同样表现优异,支持将复杂表格快速转换为可编辑的Excel格式,便于后续操作;对于图片部分,也能提供清晰展示及初步的内容识别功能。
借助在线识别平台

互联网上提供了大量在线服务,可用于处理PDF中的图像与表格内容。以Smallpdf为代表的在线平台,集成了多种PDF处理功能,在识别表格方面表现出色。用户只需上传文件,系统便可自动识别其中的表格结构,并允许导出为Excel等常用格式,极大提升了数据整理效率。针对图片内容,这些工具通常结合OCR技术,尝试提取图像中包含的文字信息。虽然识别精度会受到图像质量、排版复杂度等因素影响,但其操作简便、无需安装的特点,使其成为轻量级场景下的理想选择。
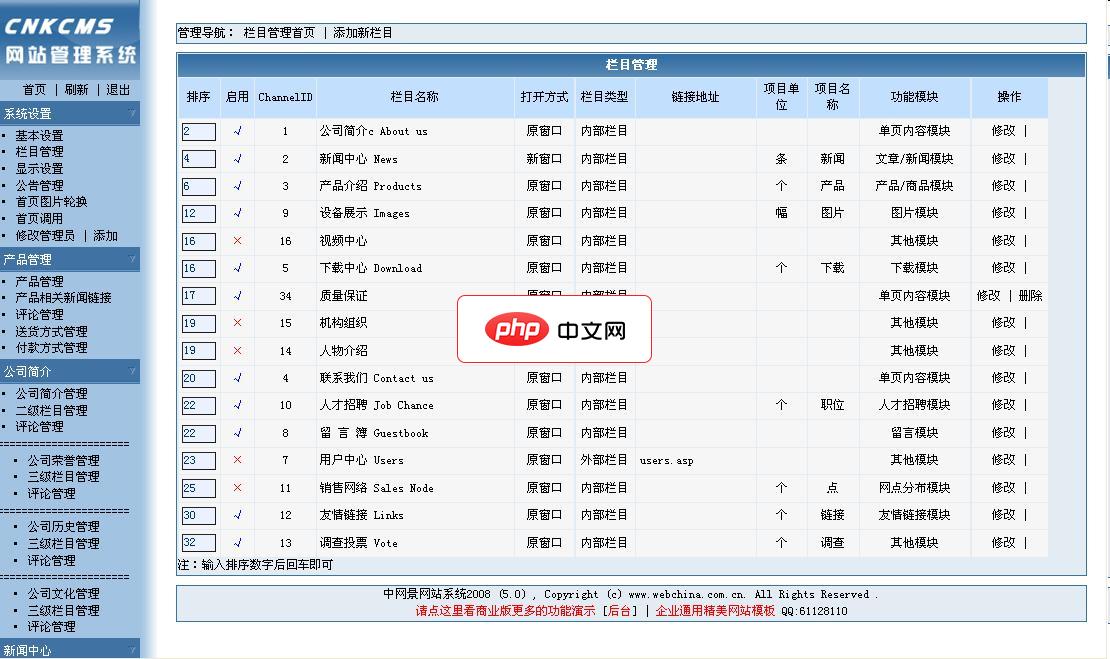
专业的企业网站管理系统,专为中小企业公司开发设计,能让企业轻松管理网站,强大的后台功能,可随意增减栏目,有多种企业常用的栏目模块功能。多级分类,管理文章,图片,文字编辑,留言管理,人才,软件下载等。可让企业会上网就会管理网站,轻松学会使用。 系统功能模块有:单页(如企业简介,联系内容等单页图文)、文章(新闻)列表、产品(图片、订单、规格说明等)、图片、下载、人才招聘、视频、机构组识、全国销售网点图
应用OCR技术实现智能识别
OCR(光学字符识别)技术是实现PDF中图片与表格内容提取的核心手段。大多数专业的PDF处理工具和在线服务都依赖于OCR引擎来完成文字与结构的还原。通过分析扫描件或嵌入图像中的文字区域,OCR可将其转化为可编辑、可搜索的文本格式。对于表格而言,先进的OCR系统不仅能识别单元格内的文字,还能重构行列布局,从而实现高保真的数据提取,显著提高文档处理的自动化水平。
实际应用中的注意事项
在进行PDF图片与表格识别时,需关注以下几点:
- 文件质量:若PDF来源于低分辨率扫描,或图片存在模糊、倾斜、对比度差等问题,将严重影响识别效果。建议尽可能使用清晰、对齐良好的原始文件。
- 格式兼容性:部分工具对加密PDF或含有图层混合内容的文件支持有限,使用前应确认其兼容范围。
- 识别准确率差异:不同工具在面对复杂表格、手写字体、艺术字或非拉丁语系语言时,识别成功率可能存在较大波动。
- 结果验证:对于关键业务数据或科研资料,建议对识别结果进行人工核对,或采用多个工具交叉比对,确保信息完整无误。
总结
总而言之,无论是利用功能强大的专业软件、便捷高效的在线工具,还是依托先进的OCR技术,合理选择并综合运用多种方式,均能实现对PDF中图片与表格内容的高效识别。掌握这些方法,将极大提升日常办公、数据分析以及学术研究的工作效率。





























