







不管你来自哪个城市,相信在你的记忆中,都有自己的「家乡话」:吴语柔软细腻、关中方言质朴厚重、四川方言幽默诙谐、粤语古雅潇洒……
某种意义上说,方言不只是一种语言习惯,也是一种情感连接、一种文化认同。我们「上网冲浪」遇到的新鲜词汇中,有不少就是来自各地方言。
当然,有些时候,方言也是一种交流「壁垒」。
在现实生活中,我们经常会看到方言导致的「鸡同鸭讲」,比如这个:
如果你关注最近科技圈的动态就会知道,当前的 AI 语音助手已经能达到「实时回复」的水准,甚至比人类反应还快。而且,AI 已经能够充分理解人类的情感,自己也能表现出各种感情。
在这样的基础上,如果语音助手能够识别并理解每一种方言,就能彻底击破沟通壁垒,与任何群体无障碍进行语言沟通。
实际上,这件事已经有人做了:近日,中国电信人工智能研究院(TeleAI)发布了业内首个支持 30 种方言自由混说的「星辰超多方言语音识别大模型」,可同时识别理解粤语、上海话、四川话、温州话等各地方言,是国内支持最多方言的语音识别大模型。
比如在以下这个会议场景中,面对多种方言的输入,星辰超多方言语音识别大模型的识别准确率达到业界领先。
首先是来自广东公司的代表,使用了粤语发言:
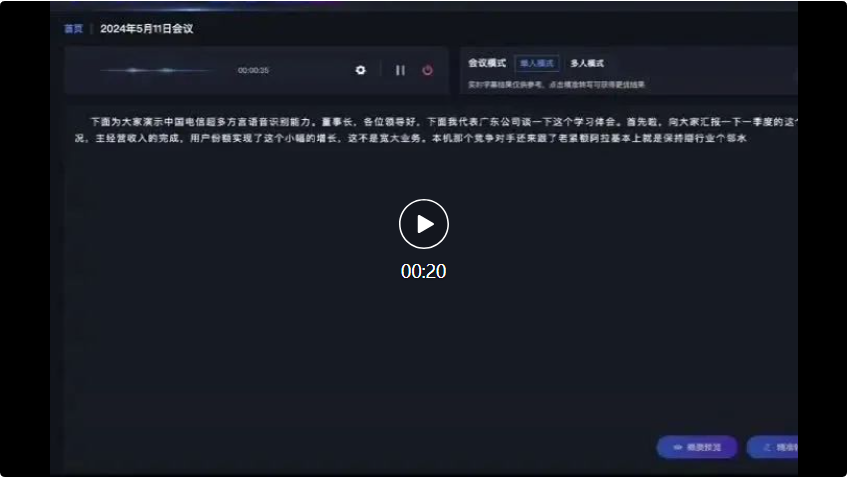 而在接下来的四川方言和山西方言的对话中,星辰超多方言语音识别大模型也能准确识别并转换为文字记录:
而在接下来的四川方言和山西方言的对话中,星辰超多方言语音识别大模型也能准确识别并转换为文字记录: 

与语音助手对话过的人都知道,针对普通话的语音识别准确率是相当不错的,但当面对重口音或者方言的时候,识别准确率会大幅下降,甚至「张冠李戴」。
为了解决这个问题,传统语音识别模型的处理方式是针对每种方言单独训练一个方言模型,这导致了同一个应用背后需要维护多个方言模型,且无法通过一个模型识别多种方言。然而后者恰恰是现实落地场景中最需要的。
一直以来深耕语音赛道的中国电信,决定挑战这一命题:打造一个更加「通用」的语音识别大模型。
30 多种方言,大模型如何拿下?
让大模型一口气学会 30 几种方言,并没有想象中的简单 —— 挑战同样存在于数据、算法、算力方面。
一方面,因为方言数据量的稀疏,不利用其他方言数据中的共有信息而单独训练某个方言模型,效果往往不尽人意。
经过在语音领域多年的积累,TeleAI 已经构建了超 30 种、超 30 万小时的高质量方言数据库,方言数据库在丰富性和高质量等层面均居于业内前列。高质量语音数据对研究者而言是一大利好,能够让模型更高效、系统地对方言进行整理归纳。更长远地看,构建高质量方言数据库,也是方言保护和研究的基础。
另一方面的挑战来自于语音识别技术。如何让用户与大模型对话就像和家人讲话一样自然,无需刻意切换普通话,无需提高音量、放慢语速,是工业界当前追求的新目标。
在中国电信 CTO、人工智能研究院院长李学龙带领下,TeleAI 自主研发了星辰语音识别大模型。团队首创「蒸馏 + 膨胀」联合训练算法,解决了超大规模多场景数据集和大规模参数条件下预训练坍缩的问题,实现 80 层模型稳定训练。同时,通过超大规模语音预训练和多方言联合建模,实现了单一模型支持 30 种方言自由混说语音识别。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

星辰语音识别大模型也是业内首个开源的基于离散语音表征的语音识别大模型,通过「从语音到 token 再到文本」的建模新范式,将推理时语音传输比特率降低了数十倍。
凭借绝对领先的性能,星辰语音识别大模型此前已经在国际上斩获了多个国际权威赛事冠军。
比如,在权威国际语音顶会 Interspeech 2024 离散语音单元建模挑战赛的 ASR 赛道(Automatic Speech Recognition,自动语音识别)中,星辰语音识别大模型团队领先于约翰霍普金斯大学、卡内基梅隆大学、英伟达等国内外知名高校与企业,一举拿下赛道冠军。
团队在这场比赛中提出的系统方案极具特色:在训练时采用了「三段式」设计,包括前端预训练模型表征调整策略(Frontend Model)、表征提取与离散化过程(Dsicrete Token Process)以及多语种识别模型训练过程(Discrete ASR Model),而在推理阶段仅使用后两段过程。
其中的表征离散化方法,可以让模型在保留语音中任务相关信息的同时,去除其余不相关信息,达到降低语音推理传输比特率、减少内存使用、提升训练效率的目的,同时也为语音多任务(如 ASR、TTS、说话人识别等)统一模型构建、多模态模型建模、说话人隐私保护等方向提供了可能的解决方案。

在业内知名的多方言语音识别数据集 KeSpeech 任务上,星辰语音识别大模型以领先之前最优结果 20% 的成绩打破纪录,实现了 92.97% 的字准确率。在 NIST(美国国家标准与技术研究院)举办的低资源粤语电话 Babel 语音识别任务上,星辰语音识别大模型也取得了业内最优结果。
在常见的算力挑战方面,星辰语音识别大模型的研发团队同样具备优势。中国电信是国内最早进入云计算领域的运营商,积累了大量算力建设和算力调度的核心技术。此外,中国电信陆续投产了京津冀智算中心、中南智算中心等多个满足大模型训练的公共智算中心。
基于这些优势条件,星辰超多方言语音识别大模型横空出世,打破了单一模型只能识别特定单一方言的困境。在多项基准测试中,星辰超多方言语音识别大模型表现出了极其优秀的能力:

在大模型技术兴起之前就广泛应用的语音助手、智能设备和客服系统,其用户体验高度依赖语音识别系统的准确率。很多海内外厂商都在这一赛道发力,但大家也会发现,在主流语种之外,使用人口达数亿级的中国方言却没有得到应有的关注,其场景价值被严重低估了。

长远来看,星辰超多方言语音识别大模型的超多方言能力可在非常广泛的社会生活场景中发挥价值。以语音交互频率较高的智能座舱场景为例,擅长各种方言的星辰超多方言语音识别大模型能够使系统更准确地识别和转录各种方言的语音输入,带来更自然流畅的交互体验,特别是在方言使用较为普遍的地区,减少「鸡同鸭讲」的误会。
从情感陪伴的角度看,大模型对方言的理解和精通,能够极大提升对话机器人类产品的陪伴质量,有效解决普通话不熟练的老年人等群体无法触达信息服务的问题。如同科幻电影《Her》中的情节,AI 能够给予人类超越真实世界中人际关系的高质量关怀。
目前,星辰超多方言语音识别大模型已经在开始融入各行各业,积极探索新兴的应用场景。比如,星辰超多方言语音识别大模型已在福建、江西、广西、北京、内蒙等地的中国电信万号智能客服系统试点应用,接入星辰超多方言语音识别大模型以后,万号智能客服秒懂 30 种方言,实现了日均处理约 200 万通电话;智能客服翼声平台接入星辰超多方言语音识别大模型的语音理解和分析能力,实现 31 省全覆盖,每天可处理 125 万通客服电话。
对于中国电信来说,还有一个非常重要的出发点:2023 年之前,当人们谈大模型技术时,公益价值很少会被提及。但在 2024 年,这一价值越来越多地「被看见」。
大模型技术的应用将很大程度上推动对方言文化的保护。在我国的 130 多种语言中,有 68 种使用人口在万人以下,有 48 种使用人口在 5000 人以下,有 25 种使用人口不足千人,有的语言只剩下十几个人甚至几个人会说。语音大模型的参与,能够帮助记录和保护濒危方言,促进方言的传承和学习。对于包含大量方言内容的历史文献和档案,方言大模型还可以辅助进行数字化和整理工作,防止文化遗产的流失。
「语音助手」全面开卷
中国电信如何领跑大模型落地之战?
大模型之战已经持续一年半之久,行业目前有一个共识:随着大模型推理成本的大幅度下降,人们将迎来大模型应用的井喷期。
在海内外众多的大模型玩家中,中国电信是很特别的一位。在这个新阶段,相比于我们熟悉的科技企业,像中国电信这样的运营商在资源优势和业务方面更具优势。
一方面,运营商有丰富的网络和算力资源,相对来说训练、推理成本更低。尤其在大模型的建设方面,更容易发挥规模的优势。另一方面,中国电信有庞大的客户群体,以及丰富的 2C、2H、2B 的信息服务业务,能够更快地推动人工智能大模型在各个领域的落地,形成新的经济增长点。这些优势使运营商有动力在人工智能领域加大投入,驱动技术进步。
在国内运营商中,中国电信是最早布局 AI 领域的一家,且坚持走科技创新、核心能力自主研发的发展路线。去年至今,从星辰语义大模型到星辰多模态大模型和星辰语音识别大模型,中国电信旗下的大模型始终保持着快速迭代,且完成了语义、语音、视觉、多模态的全模态大模型布局。

更让人打破对央企传统印象的是,中国电信还是大模型开源领域的重量级玩家。今年,TeleAI 陆续开源了 7B、12B、52B 的星辰语义大模型。今年内,千亿级星辰语义大模型也将正式开源。
沿着近年来人工智能的技术发展趋势,我们可以看到,在实现通用人工智能的过程中,语音是关键的一部分,而语音识别是其中非常重要的一环。
但我们同样意识到,语音合成技术的成熟,将成为重塑各个语音助手场景的关键。据了解,TeleAI 还同步研发了让拟人更真人的超自然语音生成大模型,实现零样本声音复刻和拟人度对齐 GPT-4o,将在语音识别和生成应用水平上进一步突破,加速通用 AI 语音助手的落地应用。 这样的全能中文语音助手,你期待吗?
这样的全能中文语音助手,你期待吗?




























