







☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

一、一种可信智能决策框架
首先和大家分享一种可信智能决策框架。
1、比预测更重要的决策
在实际的很多场景中,决策比预测更加重要。因为预测本身的目的并不只是单纯地预知未来长什么样子,而是希望通过预测去影响当下的一些关键行为和决策。
在很多领域,包括商业社会学领域,做决策非常重要,比如持续的业务增长(Continual business growth)、新商业机会发现(New business opportunity)等,如何通过数据驱动来更好地支撑最终的决策,是人工智能领域不可忽视的一部分工作。

2、无处不在的决策

决策场景无处不在。众所周知的推荐系统,给一个用户推荐什么样的商品,实际上是在所有商品里做了一个选择决策(selection decision)。在电子商务中的定价算法,比如物流服务定价等,如何为一个服务制定一个合理的价格;在医疗场景中,针对病人的症状,应该推荐使用哪种药物或者治疗方式,这些都是干预性的决策场景。
3、决策的通常做法 1:用模拟器做决策
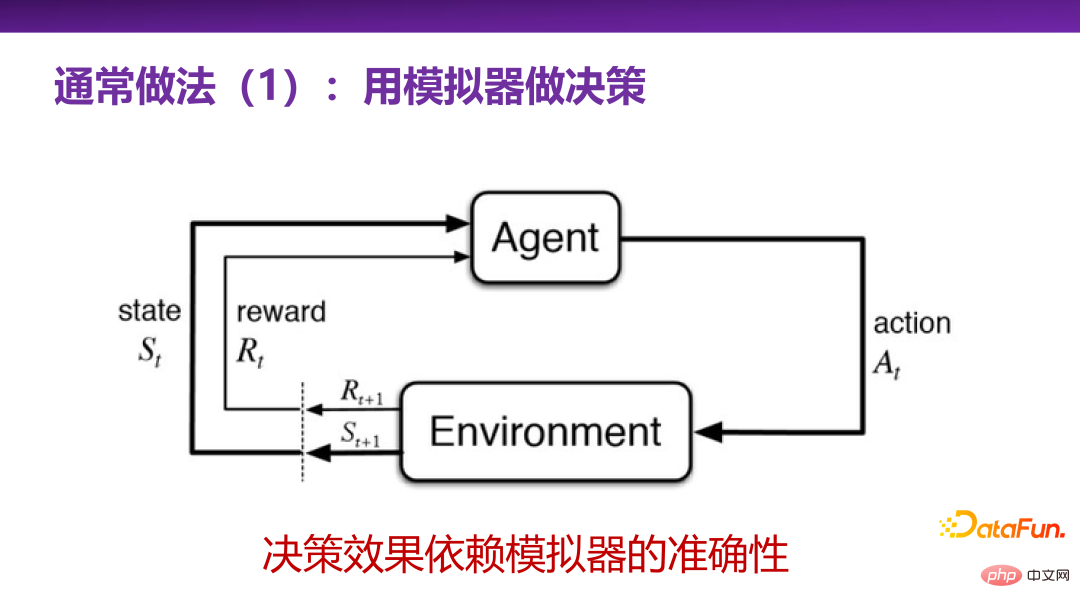
学术界和产业界对决策都不陌生,有一些常用的方法去解决或是探讨决策的问题,总结下来有两种通常的做法。
第一种通常做法是用模拟器做决策,即强化学习(reinforcement learning)。强化学习是非常强大的一类做决策的方法体系,相当于有一个真实场景(environment),或者有一个对真实场景的模拟,就可以通过智能代理(agent)不断和真实场景进行试错学习,不断探索关键行为(action),最终找到在此真实场景中收益(reward)最大的关键行为。
整套强化学习的决策体系在很多实际应用问题上,会被大家首先想到。但是在真实的应用场景下,使用强化学习最大的挑战是有没有一个很好的对真实场景的模拟器。模拟器的构建本身就是一项极具挑战性的任务。当然比如阿尔法狗(Alphago)象棋等游戏场景,总体上来讲规则是相对封闭的,去构造一个模拟器还是比较容易的。但是在商业上和真实生活中,大多是开放性的场景,比如无人驾驶,很难给出一个非常完备的模拟器。要构造出模拟器,就需要对该场景有非常深入的理解。因此,构造模拟器本身可能是比做决策、做预测更难的一个问题,这实际上是强化学习的局限性。
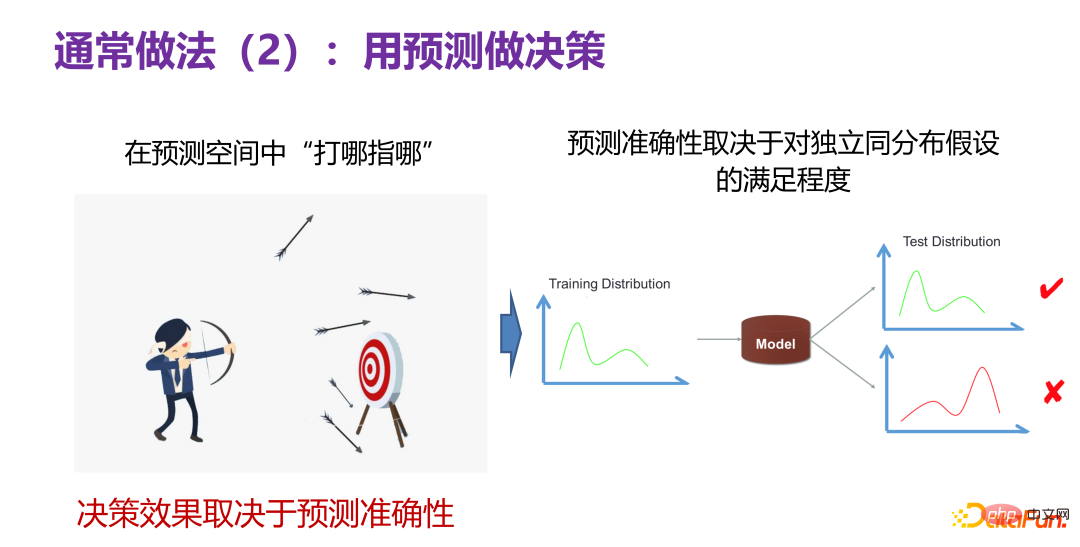
4、决策的通常做法 2:用预测做决策
另外一种通常做法就是用预测去做决策。指的是,虽然现在不知道什么样的决策好,但假如有一个预测器,能够在预测空间里边“打哪指哪”,如下图左边所示,像人射箭一样,可以先放几箭去打靶子,发现哪一箭射得比较好,就取这一箭的关键行为做相关决策。如果有这样的一个预测空间,就可以用预测做决策。
但是决策的效果取决于预测空间的准确性,到底预测得准不准。虽然在预测空间,打中了 10 次靶子,但当应用到实际的生活或产品时,中靶次数为 0,这就说明预测空间是不准的。到目前为止在预测任务上,最有信心的一个场景是在独立同分布假设下做预测,即测试分布(test distribution)和训练分布(training distribution)是同一个分布,当下有非常多强大的预测模型(prediction model),可以很好地解决实际问题。这就告诉我们:预测准确性好不好,某种程度上取决于实际场景下的测试数据和训练数据的分布是不是满足独立同分布。
继续深入思考一下预测准确性问题。假设基于历史数据 P(X,Y) 构造了一个预测模型,然后去探索一些不同的关键行为所带来收益,即如前面所述的多次射箭,看到底哪一次靶数最大。拆解一下,可以分为两类不同的情况。
第一类是给定决策变量,优化取值。事先知道了输入变量 X 中哪一个是比较好的决策变量,比如价格是 X 里面的一个决策变量,则变化价格变量的取值,用已构造出来的 P(X,Y) 预测模型去预测改变取值后的情况如何。
另外一类是寻求最优决策变量,并优化取值。事先并不知道 X 中哪一个是比较好的决策变量,场景上相对比较灵活,需要寻求最优的决策变量并优化其取值,也就是变化最优的决策变量的取值,然后看哪个取值经过预测模型预测的结果好。
基于这样的前提假设,在改变决策变量的取值时,实际上是改变了 P(X),即 P(X) 发生了变化,P(X,Y) 肯定会发生变化,那么独立同分布的假设本身就不成立了,意味着预测实际上很有可能失效。因此决策问题,如果用预测的方式来做,就会触发分布外泛化的问题,因为改变了决策变量的取值,一定会发生分布偏移(distribution shift)。在分布偏移的情况下,怎么样做预测,是属于分布外泛化的预测问题范畴,不是今天文章的主题。如果在预测领域能够解决分布外泛化的预测问题,用预测做决策也是可行的路径之一。但当下用 ID(In-Distribution)或者直接预测(direct prediction)的方法做决策,从理论上来讲是失效的,是有问题的。
5、决策问题是因果范畴
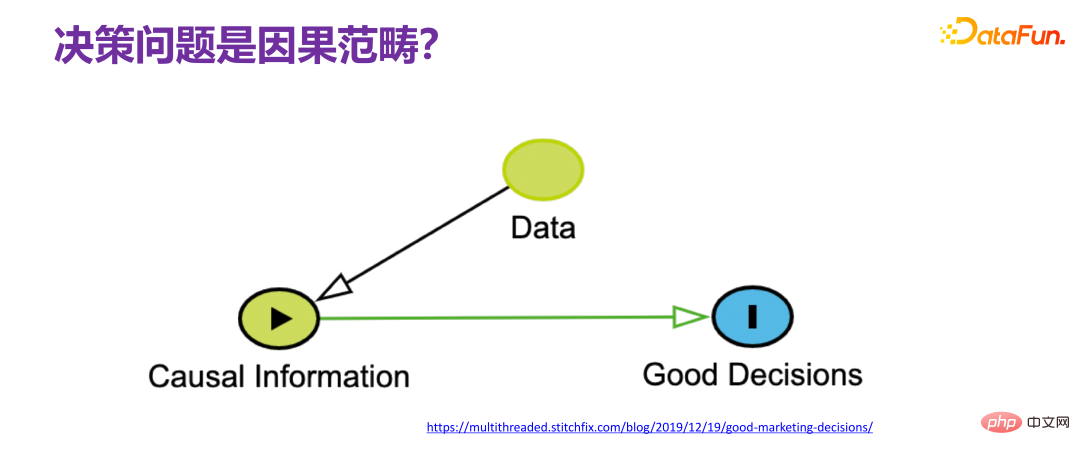
在谈到决策问题时,通常都会直接把决策问题和因果挂钩,所谓决策,就是要做一个什么样的决定,肯定要问为什么做这样一个决定,很明显存在因果链条,在学界很多学者的共识是:要解决决策问题,是绕不开因果的,也就是要从可观测的数据(observational data)上来去获取足够的因果关系信息(causal information),并理解相关的因果机制(causal mechanism),然后基于因果机制再去设计最终做决策的一些策略。如果能够把整个过程都理解得很透彻,就能完美地复原整个因果机制,这样决策就不是问题,因为实际上相当于具有了上帝视角,就不存在做决策的挑战。
6、一种对决策的框架性描述
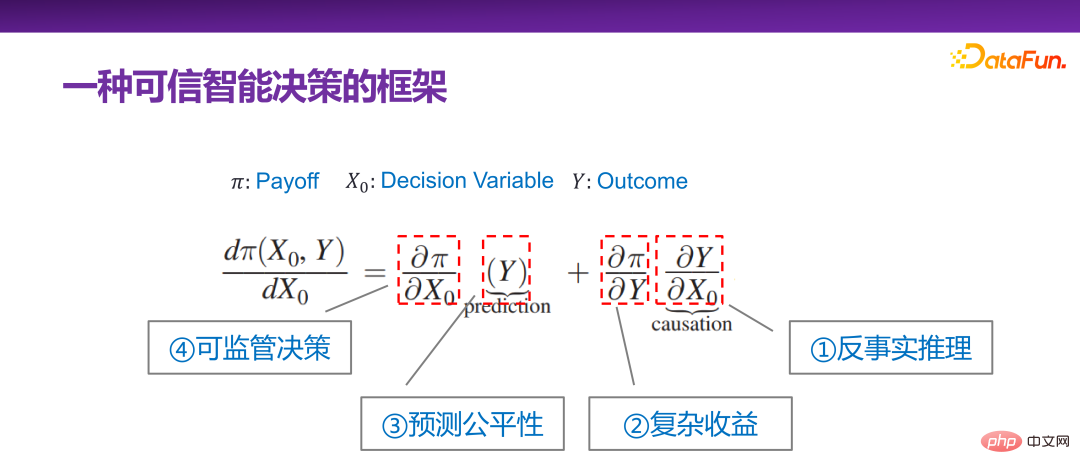
早在 2015 年,Jon Kleinberg 就在一篇论文中发表过:决策问题不是只有因果机制能解决,即不是所有的决策问题都需要因果机制去解决。Jon Kleinberg 是康奈尔大学的知名教授,著名的 hits 算法、六度风格理论等都是 Jon Kleinberg 的研究成果。Jon Kleinberg 在 2015 年发表了一篇关于决策问题的论文,“Prediction Policy Problems”[1]。他认为有些决策问题就是预测策略问题,并且为了证明该论点,给出了一种对决策的框架性描述,如下图所示。
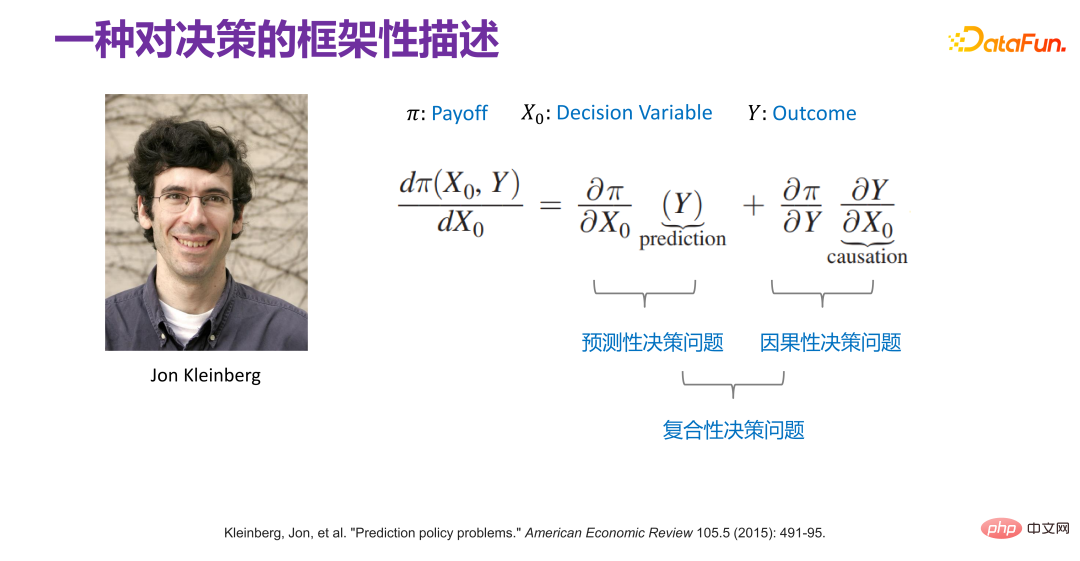
Π 是收益函数(Payoff function),x0 是决策变量(Decision Variable),Y 是因决策变量产生的结果(Outcome),Π 实际上是 x0 和 Y 的函数。那 x0 怎样变化,Π 是最大的,就可以去求这样的一个导数 : 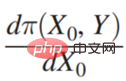
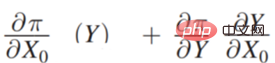
7、决策场景的两个案例

如上图所示的两种决策场景,其中 x0 是决策变量(decision variable),在两个场景下的定义是分别不同的。
先看左边的场景案例。要不要带伞,和是否下雨之间是没有关系的,即 x0 和 Y 不相关,带入到 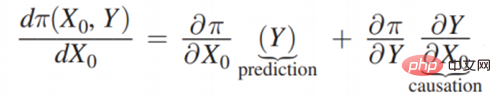
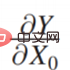
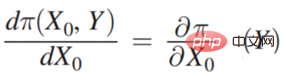
右边的案例是如果你是一个酋长,要不要花钱请人跳大神求雨,实际上很大程度上取决于“跳大神”到底能不能求到雨,是否有因果效应。等式右侧的 
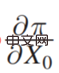
通过上述两个实际的决策案例场景,可以将决策问题划分为两类:预测性决策和因果性决策,并且 Jon Kleinberg 给出的决策问题的框架,也很好地说明了对决策的划分。
8、决策的复杂性

Jon Kleinberg 的论文中给出的一个观点是,对于预测性决策问题,就只管预测的好不好,因果机制不一定是必须的,预测模型在决策场景上很好用,对决策问题有很好的表达能力,可以把很多情况都融合在一起。但实际上决策的复杂性是超出之前对预测场景的理解的。大部分情况下,在解决预测问题时,只是尽力而为(best effort),尽量用更复杂的模型,更多的数据,希望提升最终的准确率,即尽力而为的模型(best effort model)。
但决策场景下受制约的限制因素远比预测要多。决策实际上是最后一公里,最后做出的某个决策确实会影响方方面面,影响很多利益相关主体,涉及到非常复杂的社会性、经济性的因素。例如,同样是贷款,对于不同性别、不同区域的人是否存在歧视,就是很典型的算法公平性问题。大数据杀熟,同样的商品对不同人给出不同的价格,也是一个问题。近几年来大家深有体会的信息茧房,就是不断按照用户兴趣或者相对比较窄的频谱上的兴趣,集中地对某个用户进行推荐,就会造成信息茧房。长此以往,就会出现一些不好的文化和社会现象。所以做决策时,要考虑更多的因素,才可以做出可信的决策。
9、一种可信智能决策的框架
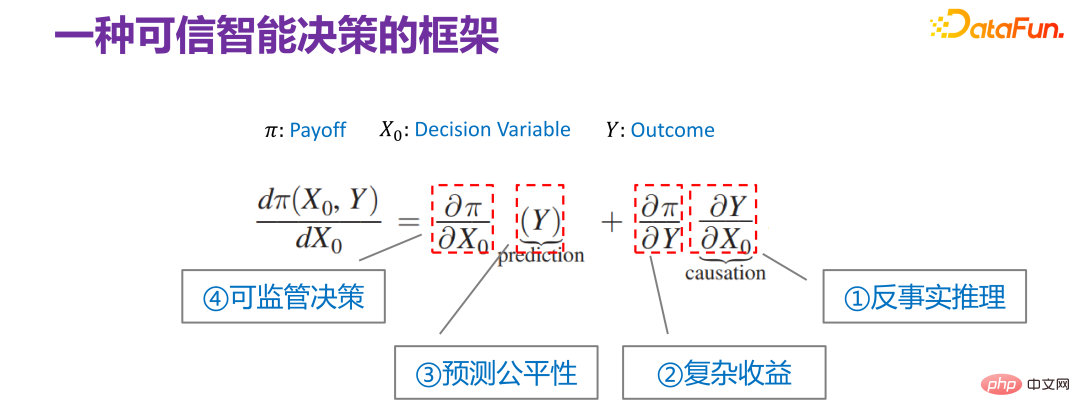
从决策可信角度对 Jon Kleinberg 给出的决策问题框架继续进行解读。虽然 Jon Kleinberg 本身提出这个决策问题框架是主张预测模型(prediction model)对于决策问题的有效性,但实际上该决策问题框架的内涵非常丰富,下面依次对该决策问题框架的各项进行解读。
首先是最右边的一项: 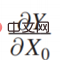
第二项是,实际相当于收益函数和模型结果之间的关系。Y 和 Π 的关系有比较简单的场景。比如进行商品推荐时,给用户推荐什么样的商品,用户会点击,优化后的最后的收益函数(Payoff function),实际上就是总体点击率。这种是两者关系比较简单的场景。但是实际业务中,不管是从平台还是从监管的角度,Y 和 Π 的关系大部分情况下是非常复杂的。比如后续会讲到的一个案例,在做平台的收益优化时,不能只看当下的点击率,要看长期收益;当看长期的收益时,Y 和 Π 的关系就会相对复杂,即复杂收益。
第三项是 Y,核心任务就是做预测(prediction),但如果预测(prediction)是用来做决策的,并且决策场景是社会属性的,比如影响到个人征信,影响到高考是不是被录取,影响到犯人是否会被释放等,那么所有的这些所谓的预测性的任务,都会要求预测必须是公平的,不能去用一些比较敏感(sensitive)的维度变量,比如性别、种族、身份等去做预测。
第四项是: 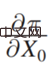
这个决策问题框架包含了不同层面的场景,也可以认为它有以上四个不同的子方向。但是总体上以上四个子方向都和可信决策是非常相关的,也就是如果要保证角色可信,必须要考虑方方面面的因素。但总体上来讲,都可以用 Jon Kleinberg 给出的框架进行统一的表述。
接下来会依次介绍可信智能决策框架下的四个子方向:反事实推理、复杂收益、预测公平性和可监管决策。
二、可信智能决策中的反事实推理
首先介绍关于可信智能决策框架下的反事实推理的一些思考和实践。

1、反事实推理

反事实推理有三个场景。
第一是策略平均效果评估(Off-Policy Evaluation)。对于一个给定的策略(policy),不希望进行 AB 测试,因为 AB 测试成本太高,因此在离线数据上评测该策略上线后,会有什么样的效果,就相当于对整个族群(population)或所有 sample 进行评测,比如对所有用户群体的一个整体效果评估。
第二是策略个体效果评估(Counterfactual Prediction),是对策略在一个个体层面的效果进行预测,不是整体平台性策略,而是针对某个个体进行一定的干预后,会有什么样的效果。
第三是策略优化(Policy Optimization),即怎么样去为一个个体选择效果最好的干预。和个体效果预测不一样,个体效果预测是先知道怎么干预,然后预测干预后的效果;策略优化是事先不知道怎么干预,但寻求怎样干预之后的效果最好。
2、策略平均效果评估
(1) 策略平均效果评估的问题框架概述
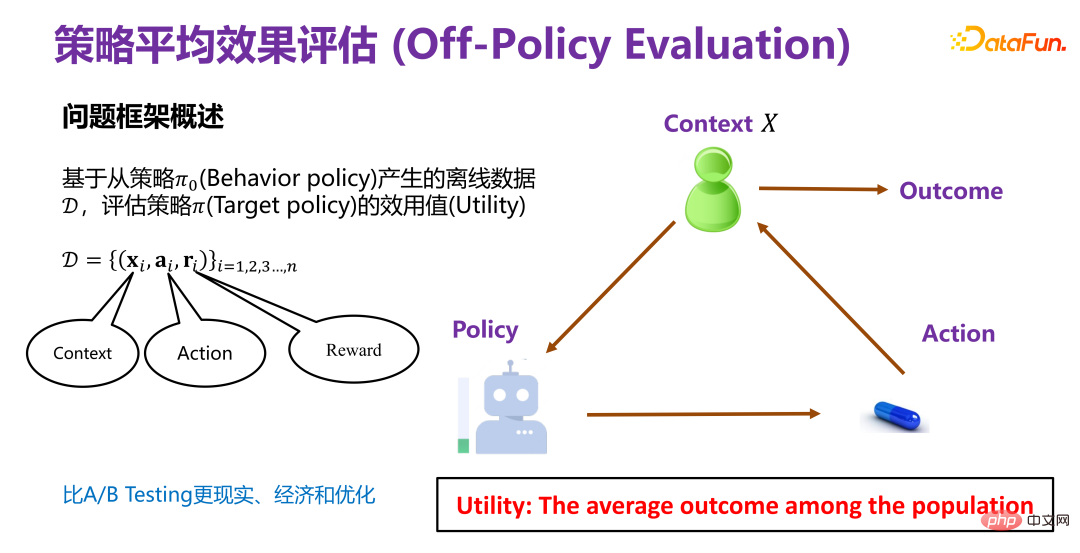
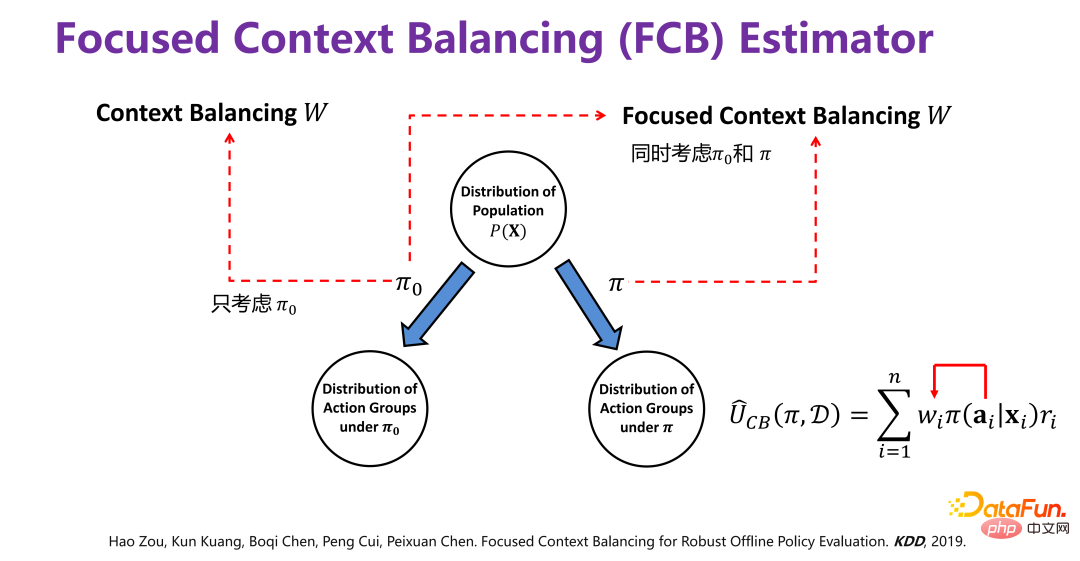
策略平均效果评估,就是基于从策略 Π0(Behavior policy)产生的离线数据 D,评估策略 Π(Target policy)的效用值(Utility)。
Π0 是已有的一个策略,比如现有推荐系统中一直在用的推荐策略。
现有策略下产生的离线数据 D 蕴含至少三个维度,如上图所示,xi 就是背景信息(Context),比如在推荐系统中的用户和商品的属性;ai 是行为, 比如推荐系统中某个商品有没有对用户曝光;ri 是最终结果(reward),比如推荐系统中用户是否最终点击或者购买商品。
基于历史数据去评测一个新的策略 Π(Target policy)的效用值(Utility)。所以整体的框架就是在某个背景(context)下,某策略(policy)会有对应的行为或者干预变量(treatment),这个干预变量(treatment)触发后,就会产生对应结果。其中,效用值(Utility)即前述的收益(Payoff),在简化 前提下,效用值就是所有用户产生的结果的总和,或者平均效果。
(2)策略平均效果评估的现有方法

传统的策略平均效果评估方法是基于结果预测的方法(Direct Method),在新的策略(policy)下给定 xi,对于主体,建议曝光还是不曝光,即对应的行为,就要预测如果进行了曝光,最终用户会不会购买,或会不会点击,即最终获得的结果(reward)。但请注意,reward 实际上是一个预测函数(prediction function),是通过历史数据得到的。历史数据中的 x、a 和 r 的联合分布(joint distribution)实际是在 Π0 下产生的,现在换了一个 Π 所产生的数据分布,再用原来 Π0 下产生的联合分布预测模型(joint distribution prediction model)去做预测,很显然这是一个 OOD(Out-of-Distribution)问题,如果后面用 OOD 预测模型,那么数据分布偏移问题有可能得到缓解,如果用一个 ID(In-Distribution)预测模型,原则上肯定会出问题。这是传统的策略平均效果评估方法。
另外一种方法是基于因果推断的,引入了倾向指数(propensity score),其核心思想是,用原始策略下的三元组(xi,ai,ri ) 在新的策略下,到底应该使用什么样的权重去加权最终产生的结果。权重应该是给定 xi,在新策略下 xi 曝光(ai)的概率和在原有策略下 xi 进行曝光(ai)的概率之比,即在新的策略下,对一个三元组所对应的结果进行加权的一个系数。该种做法最难的地方是在原始策略下,给定 xi 后,对应 ai 的概率分布其实是不知道的,因为原始策略可能很复杂,也有可能是多个策略的叠加,并没有办法显性地刻画对应的分布,因此需要进行估算,那么就会存在估算是否准确的问题,并且该估算值在分母上,会导致整个方法的分布方差(variance)非常大。另外使用倾向指数(propensity score)的估计本身就存在问题,假设倾向指数(propensity score)的函数是线性的,还是非线性的,是什么形式,估计是否准确等等。
(3)策略平均效果评估的新方法:FCB estimator
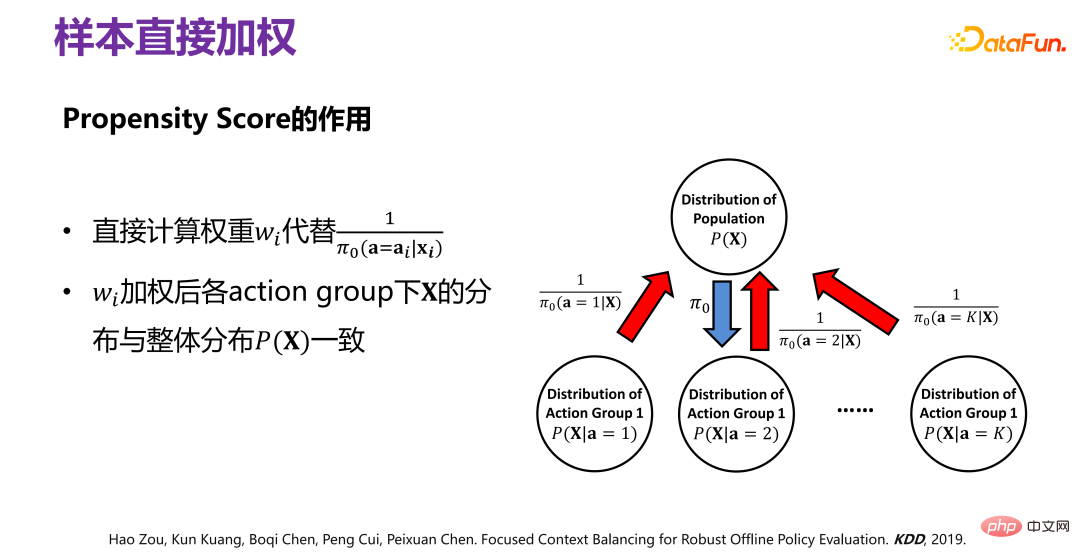
借鉴因果关系(Causality)的直接混淆变量平衡(directly confounder balancing),提出了对样本直接加权的方法,使得加权后,可以保证在各个对应行为群(action group)的分布 P(X|ai)整体上和 P(X) 是一致的。
历史数据是在给定 Π0 的情况下产生的,要去掉因 Π0 引起的分布偏差(bias),具体做法如上图所示,原始的数据分布 P(X),在 Π0 的作用下,相当于把 P(X) 划分为若干个子分布 P(X|a=1)、P(X|a=2)、P(X|a=3)、...、P(X|a=K),即不同的行为下对应 P(X) 的一个子集,是无偏的分布,每个行为群下都有因 Π0 而引起的偏差,要去掉偏差,可以通过对经 Π0 而产生的历史数据进行重加权,使得加权以后的所有子分布,都逼近原始分布 P(X),即样本直接加权。
预测一个新的策略在历史数据的前提下最终的效果会是什么样的,需要分两步进行。第一步,就是如前所述,先通过样本直接加权的方式去掉原始策略 Π0 所带来的偏差。第二步,要预测新策略 Π 的效果,也就是在新策略 Π 引起的偏差下去预估最终的效果,所以需要加上新策略 Π 引起的偏差 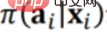
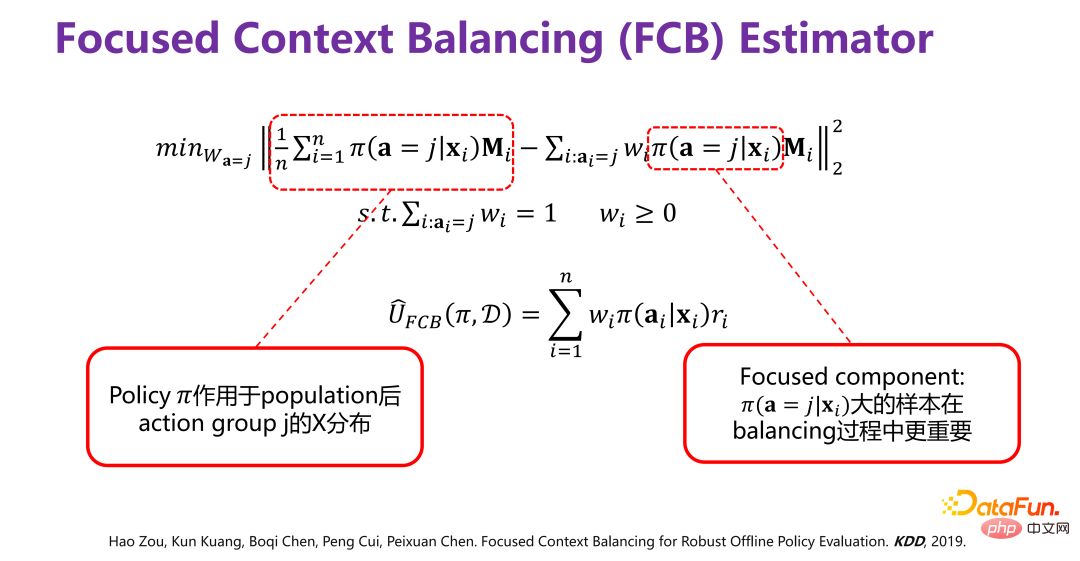
因此:
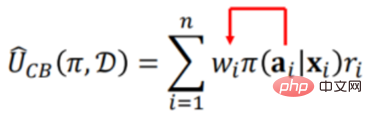
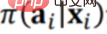
相当于把新策略的偏差加上,这样就可以预测一个新的策略最终的效果。具体方法不赘述,可以参考论文 [2]。
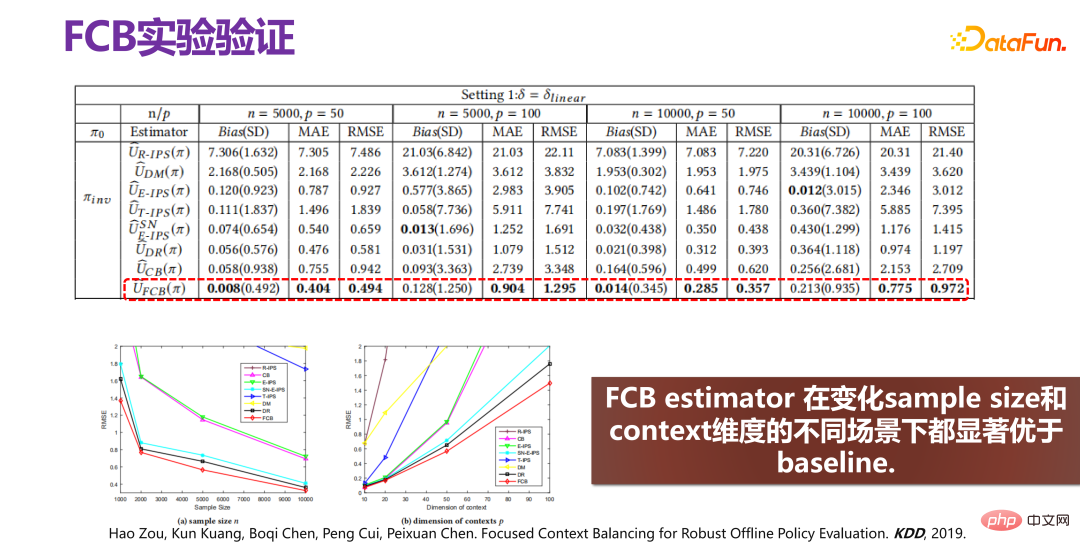
新方法 FCB Estimator 的最后提升效果如上图所示,提升效果非常明显,不管是从偏差(bias),还是 RMSE 的维度上来讲,相对提升大概有 15%-20%。FCB Estimator 在变化 sample size 和 context 维度的不同场景下都显著优于 baseline。相关论文发表在 KDD 2019 [2]。
3、策略个体效果预测
(1)策略个体效果预测的整体描述
策略个体效果预测就是要充分考虑个体异质性,直接对个体实施差别化干预,即尊重个体意志,对不同的个体实施不同的干预。
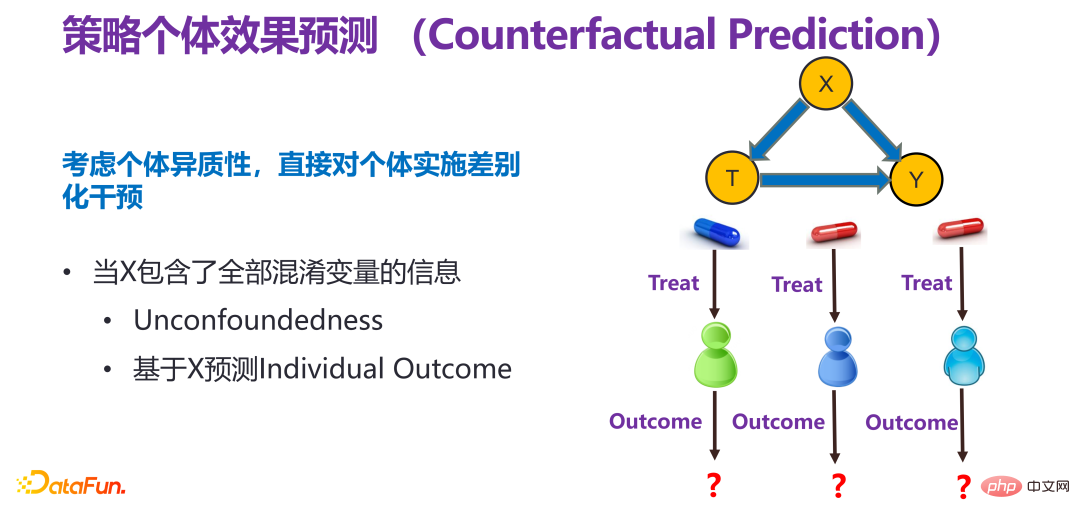
(2)现有方法的局限
策略个体效果预测常用的方法是直接对个体进行预测建模,也就是基于历史观测数据: 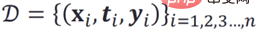

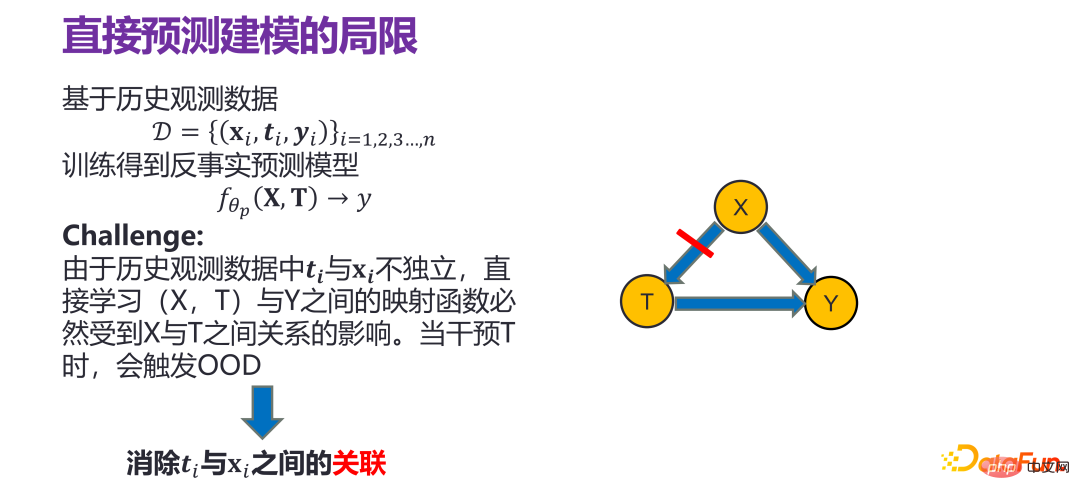
如果直接在历史数据分布下,做回归分析或者类似的模型,是有问题的。因为历史观测数据中的 ti 和 xi 并不独立,直接学习(X,T)与 Y 直接的映射函数必然受到 X 与 T 之间的关系影响,也就相当于给定了一个 xi,在历史数据里面必然对应一个 ti,比如 ti 就应该等于 0,当干预 T 时,比如硬要把 ti 改成 1,实际上就已经不服从原来的历史分布了,意味着在历史数据分布下构造出来的 ID(In-Distribution)预测模型就无效了,触发了 OOD(Out-of-Distribution)。
因此在构造所谓的预测模型时,就需要消除 X 和 T 之间的关联,分别估计 X 对 Y 的影响和 T 对 Y 的影响,这种情况,如果干预或改变了 T,和 X 就没关系,到底对 Y 会有什么影响和变化,完全由 T->Y 这条链路决定,就不存在 OOD(Out-of-Distribution)问题了。

传统做法是采用样本重加权(Sample Re-weighting)的方法来去除 X 和 T 之间的关联,有两种方法:(1)逆倾向性得分加权,(2)变量平衡。但这些方法都存在局限性:只适用于简单类型的干预变量(treatment)场景,二值或离散值。在真实的应用场景下,比如推荐系统,干预变量(treatment)维度很高,给用户推荐商品,推荐的是一个束(bundle),即从很多商品中进行推荐。当干预变量(treatment)维度很高时,使用传统的方法,把初始干预变量(raw treatment)和混淆变量(confounder) X 直接去关联,复杂度非常高,甚至样本空间不足够来去支撑高维度的干预变量(treatment)。
(3)策略个体效果预测新方法:VSR
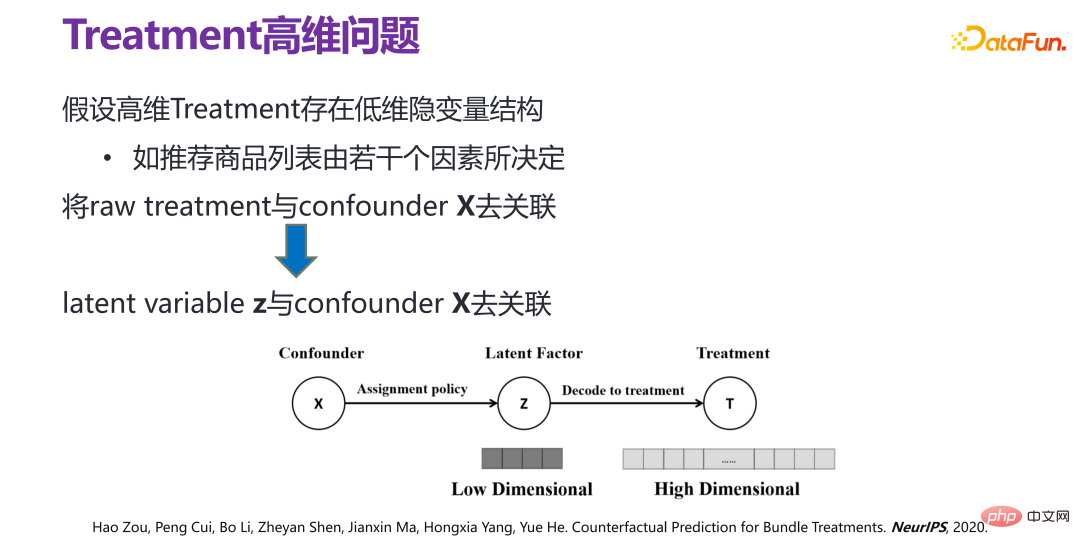
如果假设高维度的干预变量(treatment)存在低维隐变量结构,也就是给出高维度的干预变量(treatment)原则上不是随机出来的,比如推荐系统中,给定推荐策略推荐出来的商品束(bundle),里面的商品和商品之间都有各种各样的关系,存在低维隐变量结构,也就是推荐商品列表由若干因素所决定。
如果高维度的干预变量(treatment)下有一个隐变量(latent variable) z,实际上可以把问题转化为 x 与 z 之间的去关联,即和隐性因素(latent factor)之间去相关。通过这种方式,可以在有限的样本空间下实现束处理(bundle treatment)。
因此提出了新方法 VSR。VSR 方法中,首先是高维度干预变量(treatment)的隐变量 z(latent variable z)的学习,即使用变分自编码器(VAE)进行学习;然后是权重函数 w(x,z)的学习,通过样本重加权的方式对 x 和 z 之间进行去相关(decorrelation);最后在重加权的相关分布下直接使用回归分析模型(regression model),就能得到一个比较理想的策略个体效果预测模型。
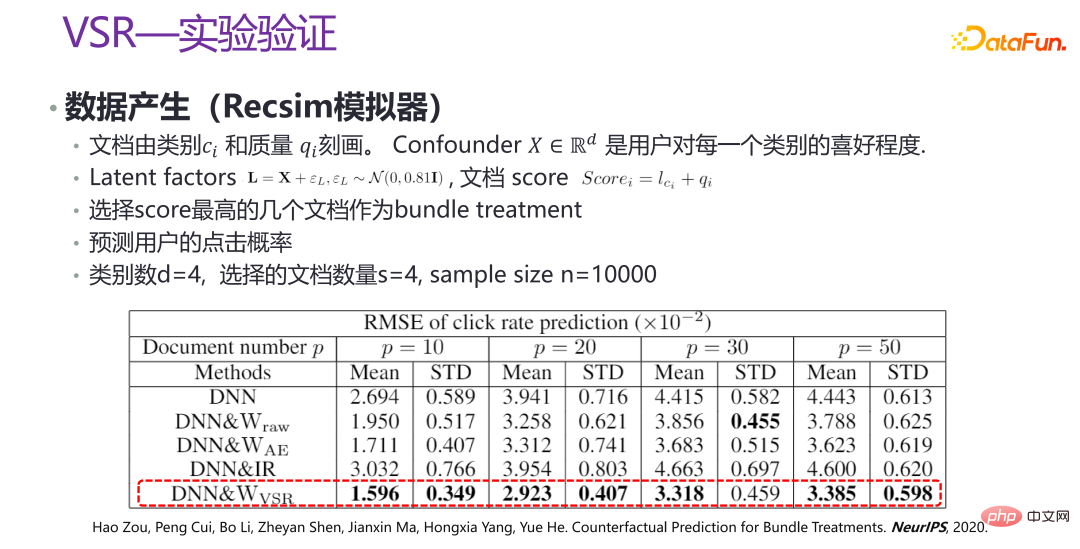
上图是新方法 VSR 的实验验证,是在一些场景下,通过 Recsim 模拟器生成部分数据,以及部分人工模拟的数据,进行验证。可以看到,在不同的 p 的取值下,VSR 的性能都相对比较稳定,相比其他方法有了很大的提升。相关论文发表在 NeurIPS 2020 [3]。
4、策略优化
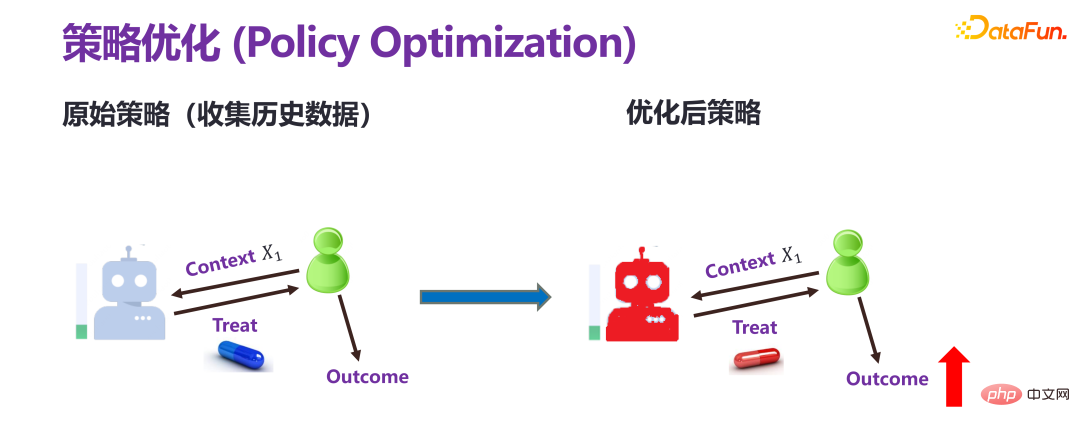
策略优化和前面两种的预测评估是有本质性区别的。预测评估都是提前给定一个策略(policy)或者个性化的干预(individual treatment),去预估最终的结果。策略优化,也叫策略学习,目标只有一个结果变大。比如收益要增长,应该施加什么样的干预。
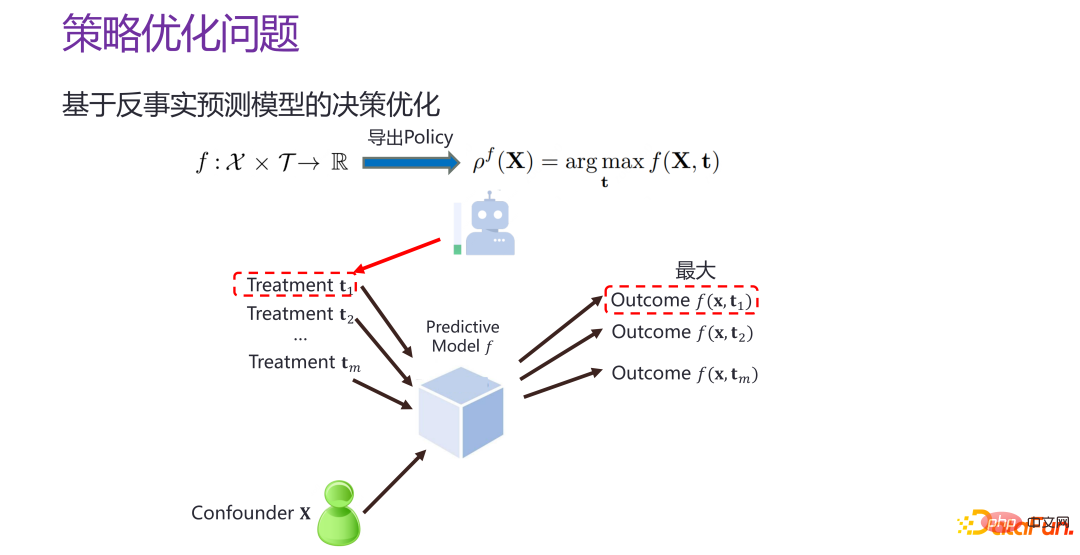
如果现在有一个反事实的个体级别的预测模型 f,即策略个体效果预测模型 f,也就是给定 xi 和 ti,就可以估计出来对应的结果,那么就可以对 T 进行遍历,t 取什么值时,f 的值最大。就相当于构造一个比较好的预测空间,在预测空间中“打哪指哪”。
但把策略优化问题退化为策略个体效果预测模型的构建,是有问题的。策略个体效果预测的目标,如前所述,实际上是相当于给定了一个干预,希望反事实预测出来的情况与真实情况的误差尽量比较小,并且对于所有给定的干预,都希望比较准确。策略优化的目标,是找到的 pf 点离真实情况上帝视角下的最优决策的结果之间的距离越小越好,并不是一个全空间的策略个体效果预测的问题,而是能不能找到离最优点比较近的区域,以及能不能准确地预测最优点。策略优化和策略个体效果预测在目标上是不一样的,存在很明显的差别。

如上图中的案例图所示,横轴是不同的干预(treatment),绿线是上帝视角下的真实函数,反映某个干预下真实的结果;红线和蓝线反映的两个预测模型下的结果。从策略个体效果预测的评价角度来看,很显然蓝线是优于红线的,蓝线离绿线的总体偏差,远小于红线离绿线的总体偏差。但从最优决策的角度来看,红线的最优结果和上帝视角的绿线的最优结果更接近,相应的干预也更接近,而蓝线的明显要更远。因此一个更好地策略个体效果预测模型,不一定能够得到一个最优的决策;并且在真实的场景下,数据量通常是不充分的,在全空间下去做优化,还是从结果的角度仅在一个子区域里做优化,优化的效果和力度是不一样的。

因此提出了策略优化的新方法 OOSR,目的是加强结果比较好的干预区域的预测力度和优化力度,而不是在全空间去做优化。因此在做优化时,在做面向结果的加权(outcome-oriented weighting)时,当前的干预离给定的已经训练下的最优解的距离越近,则优化力度更大。
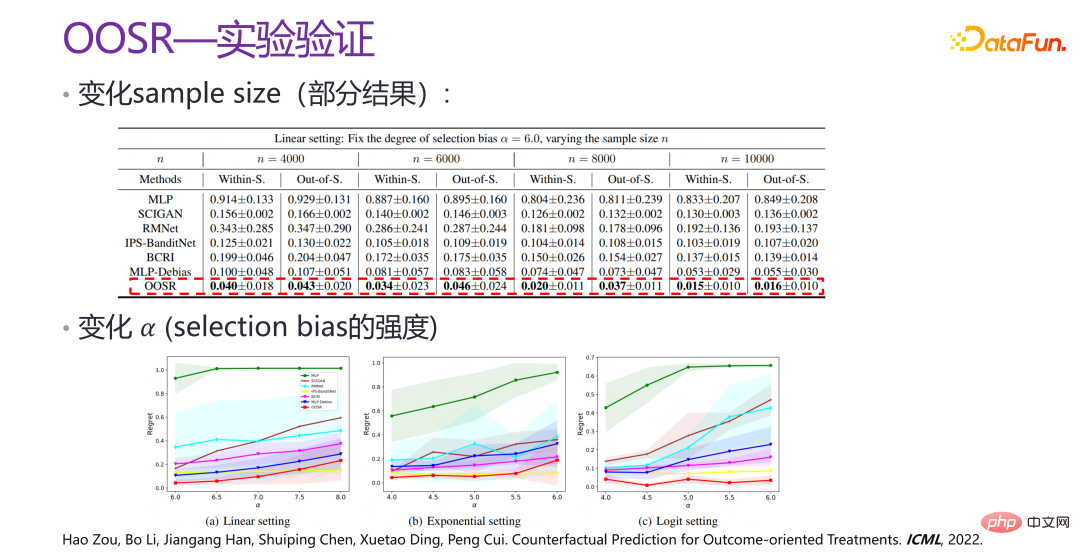
上图是 OOSR 的实验验证,可以看出,从各个角度上提升都非常明显,有几倍的提升,并且变化了 selection bias 的强度后,效果也依旧非常好。相关论文发表在 ICML 2022 [4]。
5、反事实推理总结
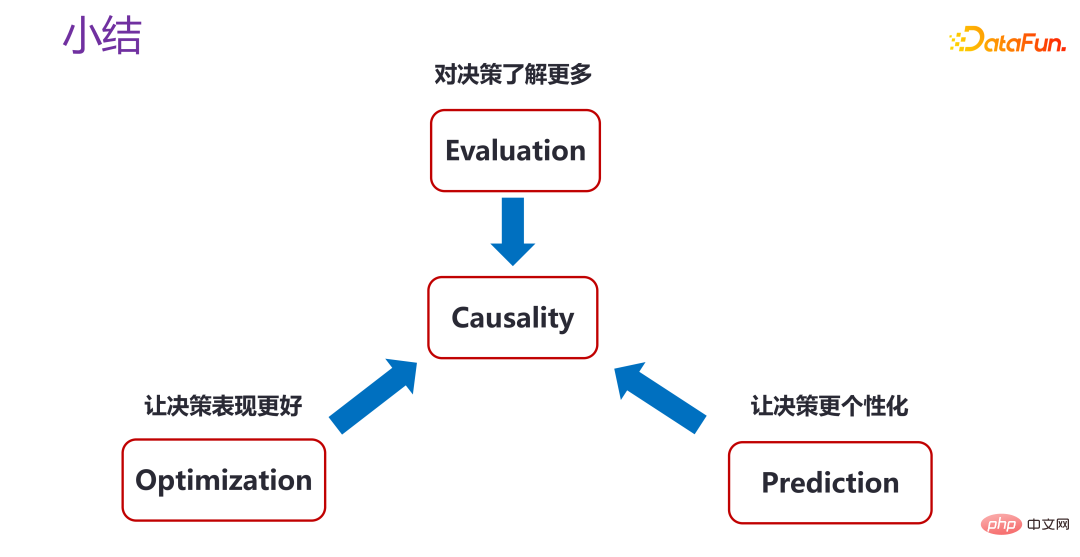
不管是做策略评估,还是策略优化、策略个体效果预测,实际上都是在利用因果关系(Causality),来对决策了解更多,让决策表现更好,或者让决策变得更加个性化。当然针对不同的场景,还有很多开放性的问题。
三、可信智能决策中的复杂收益



在研究复杂收益,即: 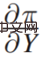


要想兼顾短期和长期收益,共同优化策略,有两个非常重要的方面。第一,要对消费者的选择模型有比较深入的理解。当给定一个用户时,是没有办法得到真实的消费者选择模型的,需要通过研究和挖掘的方式不断地探索,一个是探索消费者选择模型,另一个就是探索在消费者选择模型下怎么样最大化长期收益和短期收益,以及两者的平衡。在这个方面的工作如上两张图所示,就不展开讲了。
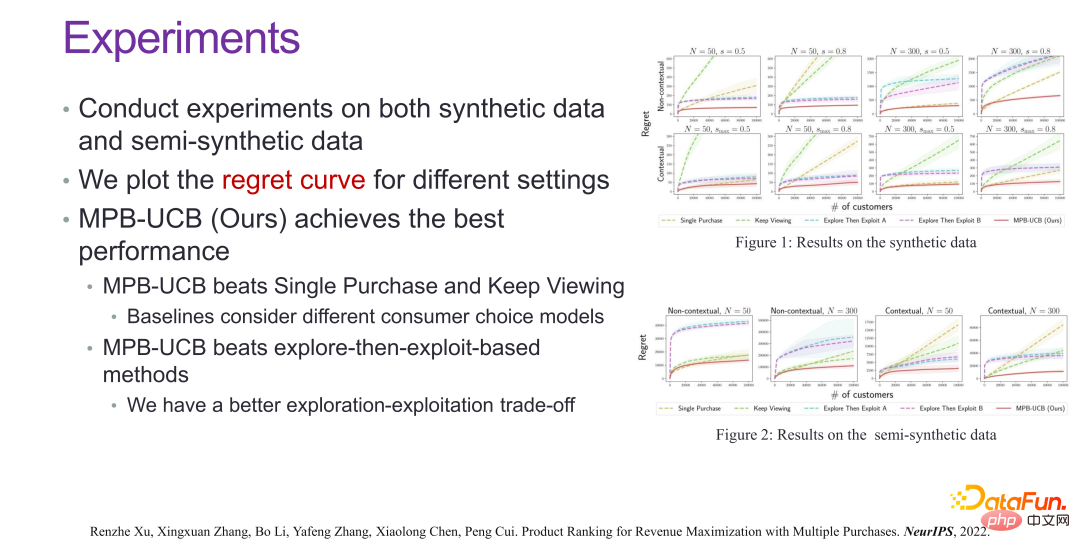
从最后的效果上来看,如上图所示,在很多真实场景都有显著的收益提升。相关论文发表在 NeurIPS 2022 [5]。
四、可信智能决策中的预测公平性

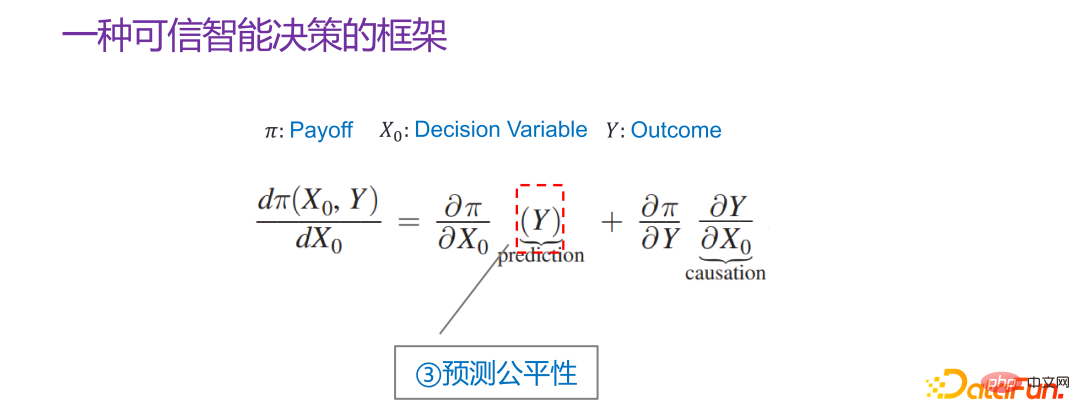

如果预测要参与到决策中,特别是面向社会性的决策,一定要兼顾预测的公平性。

关于公平性,传统的做法有 DP 和 EO,要求男女的接受概率是相等的,或者对于男女的预测能力是一样的,都是比较经典的指标。但 DP 和 EO 并不能从本质上解决公平性的问题。
比如在大学录取的案例中,理论上各个系男生和女生的录取率应该都是一样的,但实际总体上会发现女生的录取率偏低,实际上这是一种辛普森悖论。大学录取本质上是一个公平的案例,但是 DP 的指标检测出来,会认为不公平,实际上 DP 并不是一个非常完美的公平性指标。


EO 模型本质上确实是性别参与了决策,但在一个不公平的场景下,如果对于男性和女性都有一个完美预测因子,就认为是公平的。这就说明 EO 的鉴别率是不够的。

2020 年提出了有条件的公平性(conditional fairness)这一概念。有条件的公平性并不是要绝对地去保证最终结果和敏感因素(sensitive attributes)独立,而是给定某些公平性变量(fair variable),最终结果和敏感因素独立,就认为是公平的。比如专业选择,是公平的,是一个 fair variable,因为是学生主观能动性可以决定的,不存在公平性问题。
这样做带来了非常多的好处。从预测的角度来讲,公平性和预测之间实际上就是一种权衡,也就是公平性要求越强,可用的预测变量(predictive variable)就会越少。比如在 EO 的框架下,只要一个变量是在从性别到结果决策之间的链路上,是都不能用的,用了就会导致很多变量实际上预测效率非常高,但是不能做预测。但在有条件公平性下,给定了一个公平性变量,不管是不是在链路上,都可以保证预测效率可用。
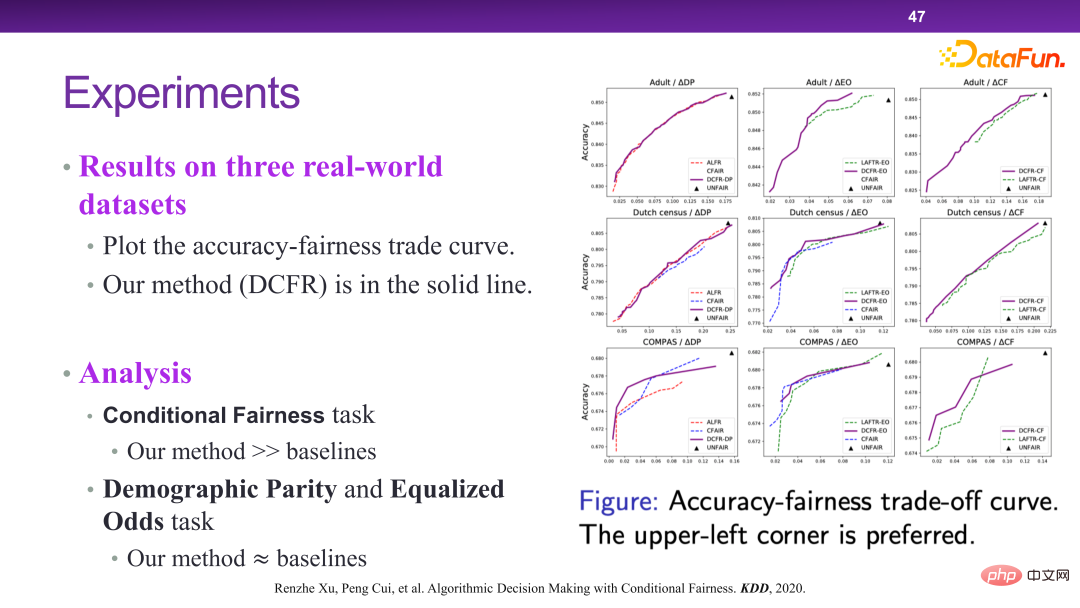
在此框架下,设计和提出了 DCFR 算法模型,如下三图所示。



下图 DCFR 算法的实验验证。从整体上看,DCFR 算法能够取得更好的预测和公平性的折中,从帕雷托最优的角度上来讲,左上的曲线实际上是更优的。相关论文发表在 KDD 2020 [6]。
五、可信智能决策中的可监管决策
最后是可信智能决策中的可监管决策。

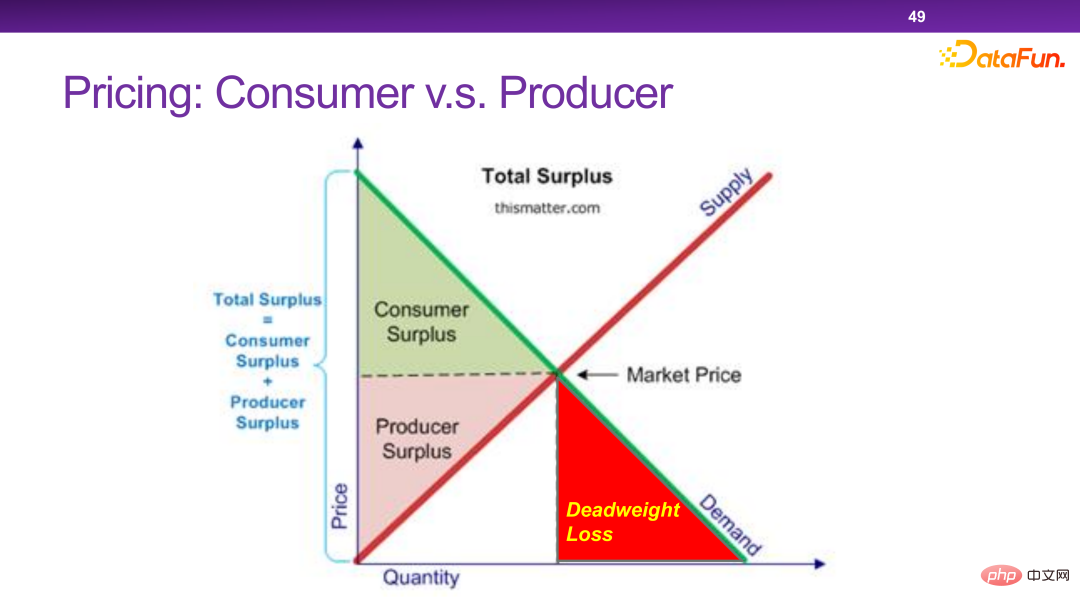
现在的平台有很多个性化定价机制。本质上来讲,个性化定价是可以最大化社会的总效率和总剩余的。但是在某一些极端情况下,商家会把所有的剩余都拿走,而不给用户留一分的剩余,这是我们不希望看到的。
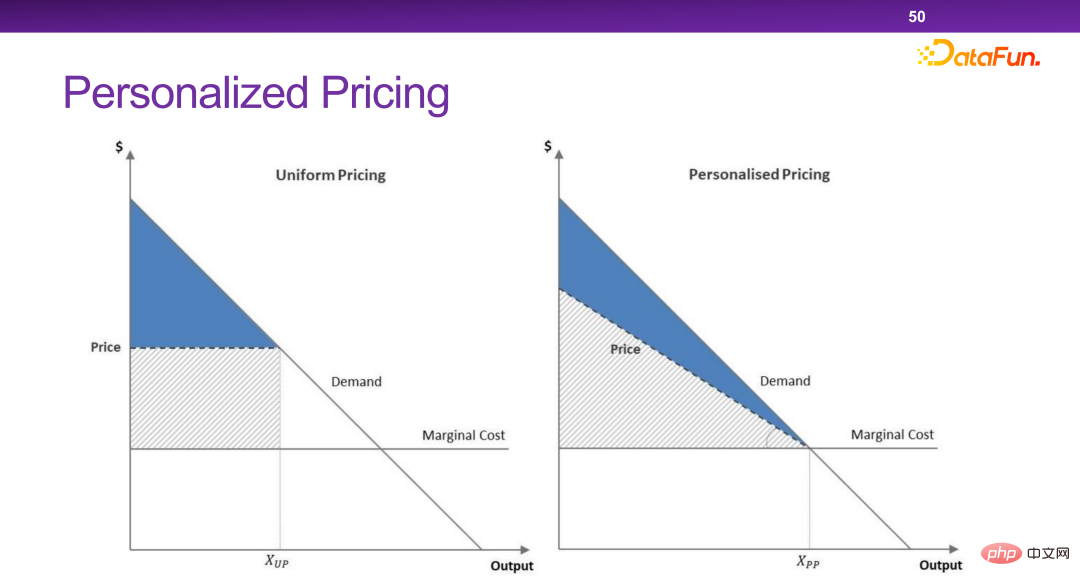

从总体上看,就是要设计出一种策略,可以使得在社会总剩余不受太大影响的情况,商家让渡一部分可视为财富的剩余给消费者。


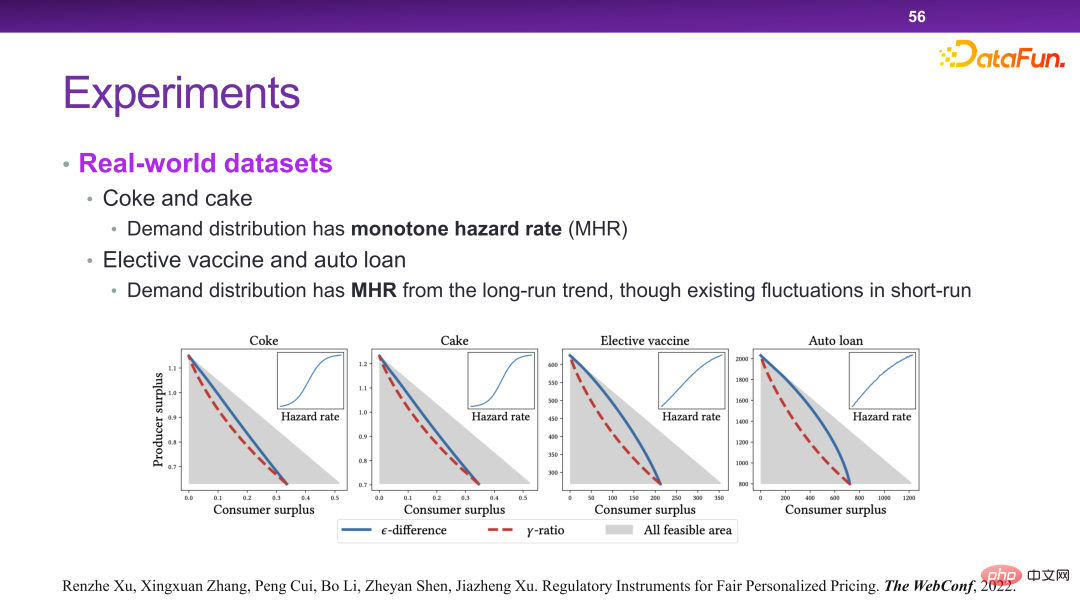
最终设计出了一种调控手段来解决这个问题,如下图所示。也就是比如同一个商品,最高价和最低价之间不能超过一个 ,或者不能超过一定的比例。理论上可以证明这样设计的规则可以实现如前所述的优化目标。
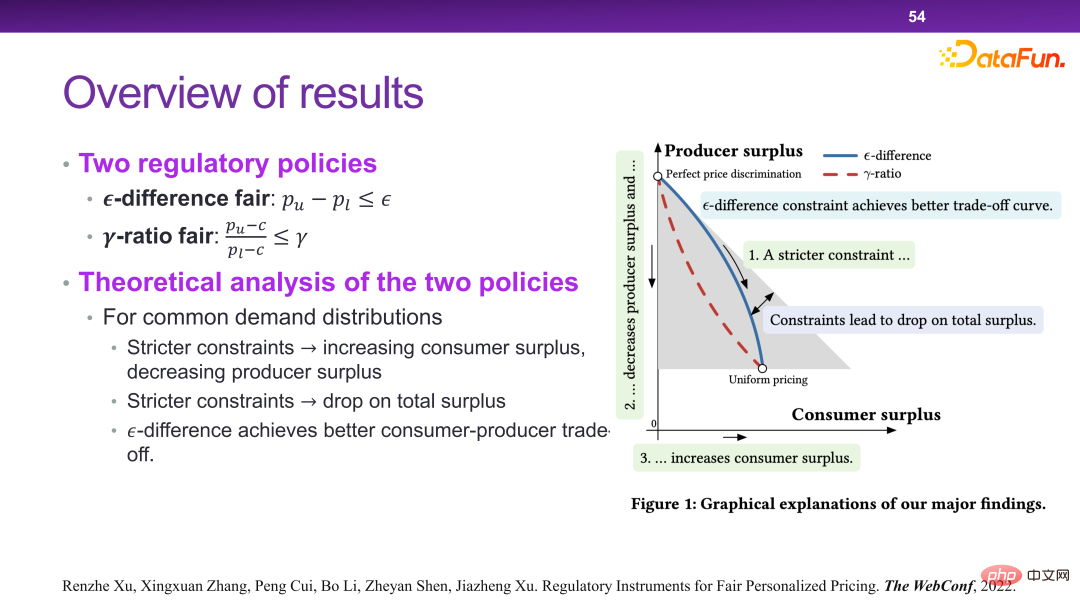
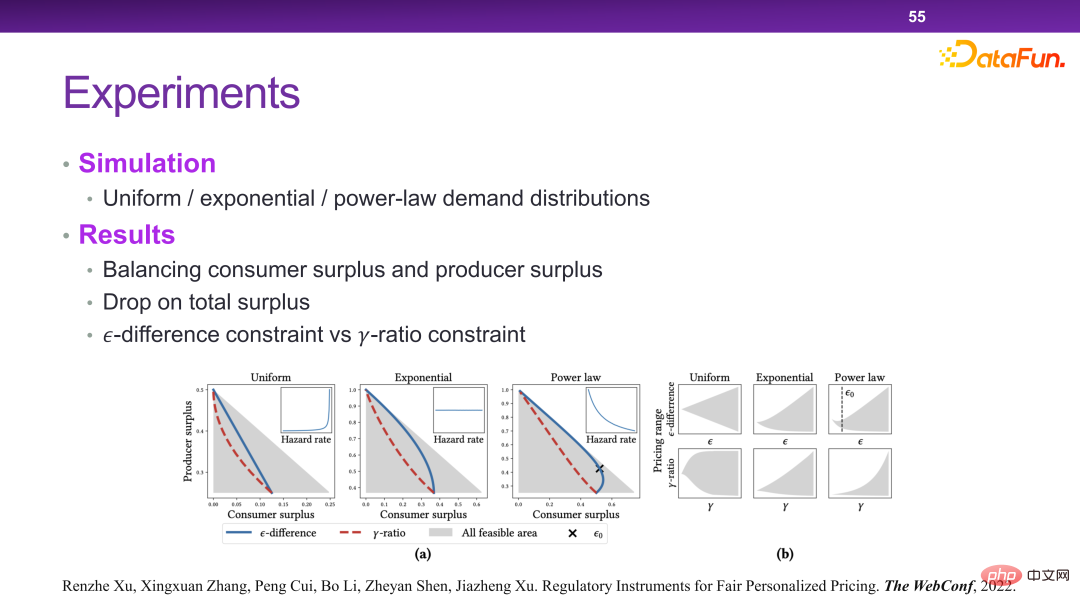
在此种场景下,本质上是通过对收益函数增加一些约束,使得在做决策的时候必须要有另一个层面的考虑。因此在这个体系下,可以把监管相关的一些策略或者工具加入进来。
六、可信智能决策的总结
以上就是在可信智能决策的这样一个框架下,在反事实推理、复杂收益、预测公平性和可监管决策各个单点上做的一些尝试。总体而言,决策的想象空间远比预测更大。在决策的领域里,还有很多和我们生活、商业息息相关的开放性问题值得探究。相关论文发表在WWW 2022 [7]。
PS: 本文涉及的很多技术细节,可以参看崔鹏老师团队近期在可信智能决策方向上所发表的论文。
七、参考文献
[1] Jon Kleinberg, Jens Ludwig, Sendhil Mullainathan, Ziad Obermeyer. Prediction Policy Problems. AER, 2015。
[2] Hao Zou, Kun Kuang, Boqi Chen, Peng Cui, Peixuan Chen. Focused Context Balancing for Robust Offline Policy Evaluation. KDD, 2019。
[3] Hao Zou, Peng Cui, Bo Li, Zheyan Shen, Jianxin Ma, Hongxia Yang, Yue He. Counterfactual Prediction for Bundle Treatments. NeurIPS, 2020。
[4] Hao Zou, Bo Li, Jiangang Han, Shuiping Chen, Xuetao Ding, Peng Cui. Counterfactual Prediction for Outcome-oriented Treatments. ICML, 2022。
[5] Renzhe Xu, Xingxuan Zhang, Bo Li, Yafeng Zhang, Xiaolong Chen, Peng Cui. Product Ranking for Revenue Maximization with Multiple Purchases. NeurIPS, 2022。
[6] Renzhe Xu, Peng Cui, Kun Kuang, Bo Li, Linjun Zhou, Zheyan Shen and Wei Cui. Algorithmic Decision Making with Conditional Fairness. KDD, 2020。
[7] Renzhe Xu, Xingxuan Zhang, Peng Cui, Bo Li, Zheyan Shen, Jiazheng Xu. Regulatory Instruments for Fair Personalized Pricing. WWW, 2022。




























