







Spark 是一种专门用于交互式查询、机器学习和实时工作负载的开源框架,而 PySpark 是 Python 使用 Spark 的库。
PySpark 是一种用于大规模执行探索性数据分析、构建机器学习管道以及为数据平台创建 ETL 的出色语言。如果你已经熟悉 Python 和 Pandas 等库,那么 PySpark 是一种很好的学习语言,可以创建更具可扩展性的分析和管道。
这篇文章的目的是展示如何使用 PySpark 构建机器学习模型。
Conda 创建 python 虚拟环境
conda将几乎所有的工具、第三方包都当作package进行管理,甚至包括python 和conda自身。Anaconda是一个打包的集合,里面预装好了conda、某个版本的python、各种packages等。
1.安装Anaconda。
打开命令行输入conda -V检验是否安装及当前conda的版本。
通过Anaconda安装默认版本的Python,3.6的对应的是 Anaconda3-5.2,5.3以后的都是python 3.7。
(https://repo.anaconda.com/archive/)
2.conda常用的命令
1) 查看安装了哪些包
conda list
2) 查看当前存在哪些虚拟环境
conda env list
conda info -e
3) 检查更新当前conda
conda update conda
3.Python创建虚拟环境
conda create -n your_env_name python=x.x
anaconda命令创建python版本为x.x,名字为your_env_name的虚拟环境。your_env_name文件可以在Anaconda安装目录envs文件下找到。
4.激活或者切换虚拟环境
打开命令行,输入python --version检查当前 python 版本。
Linux:source activate your_env_nam
Windows: activate your_env_name
5.对虚拟环境中安装额外的包
conda install -n your_env_name [package]
6.关闭虚拟环境
(即从当前环境退出返回使用PATH环境中的默认python版本)
deactivate env_name
# 或者`activate root`切回root环境
Linux下:source deactivate
7.删除虚拟环境
conda remove -n your_env_name --all
8.删除环境钟的某个包
conda remove --name $your_env_name$package_name
9.设置国内镜像
http://Anaconda.org 的服务器在国外,安装多个packages时,conda下载的速度经常很慢。清华TUNA镜像源有Anaconda仓库的镜像,将其加入conda的配置即可:
# 添加Anaconda的TUNA镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
# 设置搜索时显示通道地址
conda config --set show_channel_urls yes
10.恢复默认镜像
conda config --remove-key channels
安装 PySpark
PySpark 的安装过程和其他 python 的包一样简单(例如 Pandas、Numpy、scikit-learn)。
一件重要的事情是,首先确保你的机器上已经安装了java。然后你可以在你的 jupyter notebook 上运行 PySpark。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

探索数据
我们使用糖尿病数据集,它与美国国家糖尿病、消化和肾脏疾病研究所的糖尿病疾病有关。分类目标是预测患者是否患有糖尿病(是/否)。
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('ml-diabetes').getOrCreate()
df = spark.read.csv('diabetes.csv', header = True, inferSchema = True)
df.printSchema()
数据集由几个医学预测变量和一个目标变量 Outcome 组成。预测变量包括患者的怀孕次数、BMI、胰岛素水平、年龄等。

本程序源码为asp与acc编写,并没有花哨的界面与繁琐的功能,维护简单方便,只要你有一些点点asp的基础,二次开发易如反掌。 1.功能包括产品,新闻,留言簿,招聘,下载,...是大部分中小型的企业建站的首选。本程序是免费开源,只为大家学习之用。如果用于商业,版权问题概不负责。1.采用asp+access更加适合中小企业的网站模式。 2.网站页面div+css兼容目前所有主流浏览器,ie6+,Ch
- Pregnancies:怀孕次数
- Glucose:2小时内口服葡萄糖耐量试验的血糖浓度
- BloodPressure:舒张压(mm Hg)
- SkinThickness:三头肌皮肤褶皱厚度(mm)
- Insulin:2小时血清胰岛素(mu U/ml)
- BMI:身体质量指数(体重单位kg/(身高单位m)²)
- diabespedigreefunction:糖尿病谱系功能
- Age:年龄(年)
- Outcome:类变量(0或1)
- 输入变量: 葡萄糖、血压、BMI、年龄、怀孕、胰岛素、皮肤厚度、糖尿病谱系函数。
- 输出变量: 结果。
看看前五个观察结果。Pandas 数据框比 Spark DataFrame.show() 更漂亮。
import pandas as pd
pd.DataFrame(df.take(5),
columns=df.columns).transpose()
在 PySpark 中,您可以使用 Pandas 的 DataFrame 显示数据 toPandas()。
df.toPandas()

检查类是完全平衡的!
df.groupby('Outcome').count().toPandas()
描述性统计
numeric_features = [t[0] for t in df.dtypes if t[1] == 'int']
df.select(numeric_features)
.describe()
.toPandas()
.transpose()
自变量之间的相关性
from pandas.plotting import scatter_matrix
numeric_data = df.select(numeric_features).toPandas()
axs = scatter_matrix(numeric_data, figsize=(8, 8));
# Rotate axis labels and remove axis ticks
n = len(numeric_data.columns)
for i in range(n):
v = axs[i, 0]
v.yaxis.label.set_rotation(0)
v.yaxis.label.set_ha('right')
v.set_yticks(())
h = axs[n-1, i]
h.xaxis.label.set_rotation(90)
h.set_xticks(())

数据准备和特征工程
在这一部分中,我们将删除不必要的列并填充缺失值。最后,为机器学习模型选择特征。这些功能将分为训练和测试两部分。
缺失数据处理
from pyspark.sql.functions import isnull, when, count, col
df.select([count(when(isnull(c), c)).alias(c)
for c in df.columns]).show()
这个数据集很棒,没有任何缺失值。
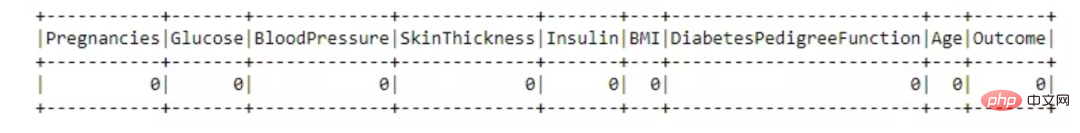
不必要的列丢弃
dataset = dataset.drop('SkinThickness')
dataset = dataset.drop('Insulin')
dataset = dataset.drop('DiabetesPedigreeFunction')
dataset = dataset.drop('Pregnancies')
dataset.show()
特征转换为向量
VectorAssembler —— 将多列合并为向量列的特征转换器。
# 用VectorAssembler合并所有特性
required_features = ['Glucose',
'BloodPressure',
'BMI',
'Age']
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(
inputCols=required_features,
outputCol='features')
transformed_data = assembler.transform(dataset)
transformed_data.show()
现在特征转换为向量已完成。
训练和测试拆分
将数据随机分成训练集和测试集,并设置可重复性的种子。
(training_data, test_data) = transformed_data.randomSplit([0.8,0.2], seed =2020)
print("训练数据集总数: " + str(training_data.count()))
print("测试数据集总数: " + str(test_data.count()))
训练数据集总数:620
测试数据集数量:148
机器学习模型构建
随机森林分类器
随机森林是一种监督学习算法,用于分类和回归。但是,它主要用于分类问题。众所周知,森林是由树木组成的,树木越多,森林越茂盛。类似地,随机森林算法在数据样本上创建决策树,然后从每个样本中获取预测,最后通过投票选择最佳解决方案。这是一种比单个决策树更好的集成方法,因为它通过对结果进行平均来减少过拟合。
from pyspark.ml.classification import RandomForestClassifier
rf = RandomForestClassifier(labelCol='Outcome',
featuresCol='features',
maxDepth=5)
model = rf.fit(training_data)
rf_predictions = model.transform(test_data)
评估随机森林分类器模型
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
multi_evaluator = MulticlassClassificationEvaluator(
labelCol = 'Outcome', metricName = 'accuracy')
print('Random Forest classifier Accuracy:', multi_evaluator.evaluate(rf_predictions))
Random Forest classifier Accuracy:0.79452
决策树分类器
决策树被广泛使用,因为它们易于解释、处理分类特征、扩展到多类分类设置、不需要特征缩放,并且能够捕获非线性和特征交互。
from pyspark.ml.classification import DecisionTreeClassifier
dt = DecisionTreeClassifier(featuresCol = 'features',
labelCol = 'Outcome',
maxDepth = 3)
dtModel = dt.fit(training_data)
dt_predictions = dtModel.transform(test_data)
dt_predictions.select('Glucose', 'BloodPressure',
'BMI', 'Age', 'Outcome').show(10)
评估决策树模型
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
multi_evaluator = MulticlassClassificationEvaluator(
labelCol = 'Outcome',
metricName = 'accuracy')
print('Decision Tree Accuracy:',
multi_evaluator.evaluate(dt_predictions))
Decision Tree Accuracy: 0.78767
逻辑回归模型
逻辑回归是在因变量是二分(二元)时进行的适当回归分析。与所有回归分析一样,逻辑回归是一种预测分析。逻辑回归用于描述数据并解释一个因二元变量与一个或多个名义、序数、区间或比率水平自变量之间的关系。当因变量(目标)是分类时,使用逻辑回归。
from pyspark.ml.classification import LogisticRegression
lr = LogisticRegression(featuresCol = 'features',
labelCol = 'Outcome',
maxIter=10)
lrModel = lr.fit(training_data)
lr_predictions = lrModel.transform(test_data)
评估我们的逻辑回归模型。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
multi_evaluator = MulticlassClassificationEvaluator(
labelCol = 'Outcome',
metricName = 'accuracy')
print('Logistic Regression Accuracy:',
multi_evaluator.evaluate(lr_predictions))
Logistic Regression Accuracy:0.78767
梯度提升树分类器模型
梯度提升是一种用于回归和分类问题的机器学习技术,它以弱预测模型(通常是决策树)的集合形式生成预测模型。
from pyspark.ml.classification import GBTClassifier
gb = GBTClassifier(
labelCol = 'Outcome',
featuresCol = 'features')
gbModel = gb.fit(training_data)
gb_predictions = gbModel.transform(test_data)
评估我们的梯度提升树分类器。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
multi_evaluator = MulticlassClassificationEvaluator(
labelCol = 'Outcome',
metricName = 'accuracy')
print('Gradient-boosted Trees Accuracy:',
multi_evaluator.evaluate(gb_predictions))
Gradient-boosted Trees Accuracy:0.80137
结论
PySpark 是一种非常适合数据科学家学习的语言,因为它支持可扩展的分析和 ML 管道。如果您已经熟悉 Python 和 Pandas,那么您的大部分知识都可以应用于 Spark。总而言之,我们已经学习了如何使用 PySpark 构建机器学习应用程序。我们尝试了三种算法,梯度提升在我们的数据集上表现最好。




























