






在Go的goroutine池中,必须通过defer+recover捕获panic,防止worker退出导致任务丢失;每个任务应封装异常处理,结合context传递上下文信息,并利用ants等库的内置机制统一管理错误,同时避免共享资源竞争引发连锁panic。

在Go语言中,goroutine池被广泛用于控制并发数量、提升资源利用率。但实际使用中,如果某个goroutine发生panic,而没有妥善处理,可能导致任务丢失、协程泄漏,甚至影响整个服务的稳定性。因此,如何在goroutine池中正确捕获和处理异常,是构建高可靠系统的关键一环。
理解goroutine中的panic传播机制
每个goroutine是独立执行的,其中发生的panic不会自动传播到主goroutine或其他协程。如果不加recover,该goroutine会直接退出,并打印堆栈信息(如果未捕获),但程序可能继续运行,造成难以察觉的问题。
在goroutine池中,worker从任务队列中取出函数执行,这些函数若包含未受保护的panic,会导致worker“死掉”,无法继续处理后续任务。因此,每个任务执行都必须包裹在defer+recover中。
示例:基础recover防护
立即学习“go语言免费学习笔记(深入)”;
在任务执行时添加异常捕获:
func safeRun(task func()) {
defer func() {
if r := recover(); r != nil {
log.Printf("goroutine panic recovered: %v", r)
}
}()
task()
}
将此safeRun作为worker执行任务的入口,可防止单个任务崩溃影响整个worker生命周期。
结合context实现优雅错误上报
仅仅recover还不够。我们需要知道哪里出了问题,便于监控和告警。可以结合context传递trace ID,或集成日志系统记录详细上下文。
常见做法是在recover后触发回调,例如通知error channel、上报metrics或写入日志系统。
示例:带错误回调的任务封装
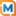
type Task struct {
Fn func()
OnPanic func(interface{})
}
func (t *Task) Run() {
defer func() {
if r := recover(); r != nil {
if t.OnPanic != nil {
t.OnPanic(r)
} else {
log.Printf("unhandled panic: %v", r)
}
}
}()
t.Fn()
}
这样可以在创建任务时指定异常处理逻辑,比如发送到集中式错误收集平台。
使用第三方库简化管理(如ants)
手动维护goroutine池复杂且易错。推荐使用成熟的开源库,如ants,它内置了panic捕获机制,并支持自定义error handler。
ants允许你在初始化池时传入选项,例如:
pool, _ := ants.NewPool(100, ants.WithPanicHandler(func(r interface{}) {
log.Printf("ants worker panic: %v", r)
}))这样所有通过该池提交的任务,即使panic也能被统一拦截,worker本身也会自动重启,保持池的健康状态。
避免共享资源导致的连锁panic
有时panic并非来自任务逻辑本身,而是由于多个goroutine竞争同一资源,如map并发写、channel关闭多次等。这类问题需要从设计上规避。
- 避免全局可变状态,尽量让任务无状态
- 使用sync.Mutex保护共享数据,或改用channel通信
- 对可能出错的操作提前校验,如判断channel是否已关闭
例如,向已关闭的channel发送数据会panic,应使用ok-ch模式判断:
select {
case ch <- data:
default:
log.Println("channel full or closed")
}
基本上就这些。goroutine池中的异常处理核心原则是:每个任务执行都要有recover,配合上下文追踪和错误回调,再借助成熟库降低出错概率。只要做好防御,就能在高并发下保持系统稳定。不复杂但容易忽略。




























