






自适应傅里叶神经算子(AFNO)是一种高效令牌混合器,基于傅里叶神经算子(FNO)改进,在傅里叶域实现令牌混合。通过块对角结构、自适应权重共享及软阈值稀疏化频率模式,解决了FNO在视觉任务中的效率问题,具有准线性复杂度和线性内存。在少样本分割、城市景观分割等任务中,效率与准确性均优于自注意力机制。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

自适应傅里叶神经算子:Transfomer的有效令牌混合器
摘要
视觉Transformer在表征学习中取得了巨大的成功。 这主要是由于通过自注意力有效地混合了表征。 然而,这与像素数成二次比例,这对于高分辨率输入来说变得不可行。 为了应对这一挑战,我们提出了自适应傅立叶神经算子(AFNO)作为一种有效的令牌混合器,它可以在傅立叶域学习混合。 AFNO是基于算子学习的一个基元,它允许我们将令牌混合看做一个连续的全局卷积,而不依赖于输入分辨率。 这一原理以前被用于设计FNO,它在傅立叶域有效地解决了全局卷积,并在学习具有挑战性的偏微分方程方面显示出了希望。 为了解决视觉表示学习中的挑战,如图像的不连续性和高分辨率输入,我们对FNO提出了原则性的结构修改,从而提高了内存和计算效率。 这包括在通道混合权重上施加块对角结构,在令牌之间自适应地共享权重,以及通过软阈值化和收缩来稀疏频率模式。 所得到的模型具有高度的并行性和准线性复杂度,并且在序列大小上具有线性内存。 对于少样本分割,AFNO在效率和准确性方面都优于自注意力机制。 对于使用SegFormer-B3主干的城市景观分割,AFNO可以处理65K的序列大小,并且性能优于其他自注意力机制。
1. AFNO

1.1 FNO
具有平移不变性的核具有一个理想性质,即它可以分解成特征函数的线性组合。根据卷积定理,空间域中的全局卷积操作相当于特征变换域中的乘法。利用这一定理的一个典型模型就是傅里叶神经算子(FNO)。其连续形式定义如下:
K(X)(s)=F−1(F(κ)⋅F(X))(s)∀s∈D,
受FNO启发,本文使用离散FNO来对图像进行处理,定义如下:
step(1).token mixingstep(2).channel mixingstep(3).token demixingzm,nz~m,nym,n=[DFT(X)]m,n=Wm,nzm,n=[IDFT(Z~)]m,n
简单将FNO用于视觉任务有如下几个缺点:
- 由于每个Token都有自己的通道混合权重且参数是 O(Nd2) ,因此难以随图像分辨率一起缩放
- 权重是静态的,因此会削弱泛化能力
1.2 AFNO
为解决上述问题,本文提出了一种新的FNO——AFNO,主要有如下几点改进:

- 对权重W使用块对角结构。类似多头注意力,将权重W分成多个块。
z~m,n(ℓ)=Wm,n(ℓ)zm,n(ℓ),ℓ=1,…,k
- 权重共享。使用MLP来自适应样本(?有点勉强),同时进行权重共享以减少开销
z~m,n=MLP(zm,n)=W2σ(W1zm,n)+b
- 软阈值与收缩。图像在傅立叶域内具有稀疏性,大部分能量集中在低频模式附近。 因此,可以根据令牌对最终任务的重要性自适应地mask令牌。 这可以使用表达性来表示重要的令牌。 为了稀疏化标记,本文使用非线性Lasso Tibshirani通道混合,而不是线性组合,如下所示
min∥z~m,n−Wm,nzm,n∥2+λ∥z~m,n∥1
该操作可以使用softshrink激活函数来解决。
\begin{align} \tilde{z}_{m, n} & = S_{\lambda}\left(W_{m, n} z_{m, n}\right) \\ S_{\lambda}(x) & = \operatorname{sign}(x) \max \{|x|-\lambda, 0\} \end{align}2. 代码复现
2.1 下载并导入所需的库
%matplotlib inlineimport paddleimport numpy as npimport matplotlib.pyplot as pltfrom paddle.vision.datasets import Cifar10from paddle.vision.transforms import Transposefrom paddle.io import Dataset, DataLoaderfrom paddle import nnimport paddle.nn.functional as Fimport paddle.vision.transforms as transformsimport osimport matplotlib.pyplot as pltfrom matplotlib.pyplot import figureimport itertoolsfrom functools import partialimport math
2.2 创建数据集
train_tfm = transforms.Compose([
transforms.RandomResizedCrop(224, scale=(0.6, 1.0)),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
paddle.vision.set_image_backend('cv2')# 使用Cifar10数据集train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)print("train_dataset: %d" % len(train_dataset))print("val_dataset: %d" % len(val_dataset))
train_dataset: 50000 val_dataset: 10000
batch_size=256
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
2.3 模型的创建
2.3.1 标签平滑
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss return loss.mean()
2.3.2 DropPath
def drop_path(x, drop_prob=0.0, training=False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ...
"""
if drop_prob == 0.0 or not training: return x
keep_prob = paddle.to_tensor(1 - drop_prob)
shape = (paddle.shape(x)[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor) # binarize
output = x.divide(keep_prob) * random_tensor return outputclass DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
2.3.3 AFNO模型的创建
class AFNO2D(nn.Layer):
"""
hidden_size: channel dimension size
num_blocks: how many blocks to use in the block diagonal weight matrices (higher => less complexity but less parameters)
sparsity_threshold: lambda for softshrink
hard_thresholding_fraction: how many frequencies you want to completely mask out (lower => hard_thresholding_fraction^2 less FLOPs)
"""
def __init__(self, hidden_size, num_blocks=8, sparsity_threshold=0.01, hard_thresholding_fraction=1, hidden_size_factor=1):
super().__init__() assert hidden_size % num_blocks == 0, f"hidden_size {hidden_size} should be divisble by num_blocks {num_blocks}"
self.hidden_size = hidden_size
self.sparsity_threshold = sparsity_threshold
self.num_blocks = num_blocks
self.block_size = self.hidden_size // self.num_blocks
self.hard_thresholding_fraction = hard_thresholding_fraction
self.hidden_size_factor = hidden_size_factor
self.scale = 0.02
self.w1 = self.create_parameter(shape=(2, self.num_blocks, self.block_size, self.block_size * self.hidden_size_factor), default_initializer=nn.initializer.TruncatedNormal(std=.02))
self.b1 = self.create_parameter(shape=(2, self.num_blocks, self.block_size * self.hidden_size_factor), default_initializer=nn.initializer.TruncatedNormal(std=.02))
self.w2 = self.create_parameter(shape=(2, self.num_blocks, self.block_size * self.hidden_size_factor, self.block_size), default_initializer=nn.initializer.TruncatedNormal(std=.02))
self.b2 = self.create_parameter(shape=(2, self.num_blocks, self.block_size), default_initializer=nn.initializer.TruncatedNormal(std=.02)) def forward(self, x, spatial_size=None):
bias = x
B, N, C = x.shape if spatial_size == None:
H = W = int(math.sqrt(N)) else:
H, W = spatial_size
x = x.reshape((B, H, W, C))
x = paddle.fft.rfft2(x, axes=(1, 2), norm="ortho")
x = x.reshape((B, x.shape[1], x.shape[2], self.num_blocks, self.block_size))
o1_real = paddle.zeros([B, x.shape[1], x.shape[2], self.num_blocks, self.block_size * self.hidden_size_factor])
o1_imag = paddle.zeros([B, x.shape[1], x.shape[2], self.num_blocks, self.block_size * self.hidden_size_factor])
o2_real = paddle.zeros(x.shape)
o2_imag = paddle.zeros(x.shape)
total_modes = N // 2 + 1
kept_modes = int(total_modes * self.hard_thresholding_fraction)
o1_real[:, :, :kept_modes] = F.relu(
paddle.einsum('bhwnc, ncd->bhwnd', x[:, :, :kept_modes].real(), self.w1[0]) - \
paddle.einsum('bhwnc, ncd->bhwnd', x[:, :, :kept_modes].imag(), self.w1[1]) + \
self.b1[0]
)
o1_imag[:, :, :kept_modes] = F.relu(
paddle.einsum('bhwnc, ncd->bhwnd', x[:, :, :kept_modes].imag(), self.w1[0]) + \
paddle.einsum('bhwnc, ncd->bhwnd', x[:, :, :kept_modes].real(), self.w1[1]) + \
self.b1[1]
)
o2_real[:, :, :kept_modes] = (
paddle.einsum('bhwnc, ncd->bhwnd', o1_real[:, :, :kept_modes], self.w2[0]) - \
paddle.einsum('bhwnc, ncd->bhwnd', o1_imag[:, :, :kept_modes], self.w2[1]) + \
self.b2[0]
)
o2_imag[:, :, :kept_modes] = (
paddle.einsum('bhwnc, ncd->bhwnd', o1_imag[:, :, :kept_modes], self.w2[0]) + \
paddle.einsum('bhwnc, ncd->bhwnd', o1_real[:, :, :kept_modes], self.w2[1]) + \
self.b2[1]
)
x = paddle.stack([o2_real, o2_imag], axis=-1)
x = F.softshrink(x, threshold=self.sparsity_threshold)
x = paddle.as_complex(x)
x = x.reshape((B, x.shape[1], x.shape[2], C))
x = paddle.fft.irfft2(x, s=(H, W), axes=(1, 2), norm="ortho")
x = x.reshape((B, N, C)) return x + bias
class Mlp(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop) def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x) return x
class Block(nn.Layer):
def __init__(self, dim, hidden_size, fno_blocks, mlp_ratio=4., drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, h=14, w=8, use_fno=False, use_blocks=False):
super().__init__()
self.norm1 = norm_layer(dim)
self.filter = AFNO2D(hidden_size=hidden_size, num_blocks=fno_blocks, sparsity_threshold=0.01, hard_thresholding_fraction=1, hidden_size_factor=1)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop) def forward(self, x):
residual = x
x = self.norm1(x)
x = self.filter(x)
x = x + residual
residual = x
x = self.norm2(x)
x = self.mlp(x)
x = self.drop_path(x)
x = x + residual return x
def to_2tuple(x):
return (x, x)class PatchEmbed(nn.Layer):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x):
B, C, H, W = x.shape # FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \ f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose([0, 2, 1]) return x
class DownLayer(nn.Layer):
def __init__(self, img_size=56, dim_in=64, dim_out=128):
super().__init__()
self.img_size = img_size
self.dim_in = dim_in
self.dim_out = dim_out
self.proj = nn.Conv2D(dim_in, dim_out, kernel_size=2, stride=2)
self.num_patches = img_size * img_size // 4
def forward(self, x):
B, N, C = x.size()
x = x.reshape((B, self.img_size, self.img_size, C)).transpose([0, 3, 1, 2])
x = self.proj(x).transpose([0, 2, 3, 1])
x = x.reshape((B, -1, self.dim_out)) return x
class AFNONet(nn.Layer):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=384, depth=12,
mlp_ratio=4., representation_size=None, uniform_drop=False,
drop_rate=0., drop_path_rate=0., norm_layer=None,
dropcls=0, use_fno=False, use_blocks=False, hidden_size=384, fno_blocks=2):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
norm_layer = norm_layer or partial(nn.LayerNorm, epsilon=1e-6)
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.pos_embed = self.create_parameter(shape=(1, num_patches, embed_dim), default_initializer=nn.initializer.TruncatedNormal(std=.02))
self.pos_drop = nn.Dropout(p=drop_rate)
h = img_size // patch_size
w = h // 2 + 1
if uniform_drop: # print('using uniform droppath with expect rate', drop_path_rate)
dpr = [drop_path_rate for _ in range(depth)] # stochastic depth decay rule
else: # print('using linear droppath with expect rate', drop_path_rate * 0.5)
dpr = [x.item() for x in paddle.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
# dpr = [drop_path_rate for _ in range(depth)] # stochastic depth decay rule
self.blocks = nn.LayerList([
Block(
dim=embed_dim, hidden_size=hidden_size, fno_blocks=fno_blocks, mlp_ratio=mlp_ratio,
drop=drop_rate, drop_path=dpr[i], norm_layer=norm_layer, h=h, w=w, use_fno=use_fno, use_blocks=use_blocks) for i in range(depth)])
self.norm = norm_layer(embed_dim) # Representation layer
if representation_size:
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
('fc', nn.Linear(embed_dim, representation_size)),
('act', nn.Tanh())
])) else:
self.pre_logits = nn.Identity() # Classifier head
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity() if dropcls > 0: print('dropout %.2f before classifier' % dropcls)
self.final_dropout = nn.Dropout(p=dropcls) else:
self.final_dropout = nn.Identity()
self.apply(self._init_weights) def _init_weights(self, m):
tn = nn.initializer.TruncatedNormal(std=.02)
zero = nn.initializer.Constant(0.0)
one = nn.initializer.Constant(1.0) if isinstance(m, nn.Linear):
tn(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zero(m.bias) elif isinstance(m, nn.LayerNorm):
zero(m.bias)
one(m.weight) def forward_features(self, x):
B = x.shape[0]
x = self.patch_embed(x)
x = x + self.pos_embed
x = self.pos_drop(x) for blk in self.blocks:
x = blk(x)
x = self.norm(x).mean(1) return x def forward(self, x):
x = self.forward_features(x)
x = self.final_dropout(x)
x = self.head(x) return x
2.3.4 模型的参数
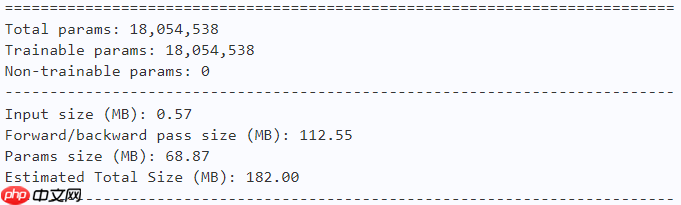
model = AFNONet(num_classes=10) paddle.summary(model, (1, 3, 224, 224))
2.4 训练
learning_rate = 0.001n_epochs = 100paddle.seed(42) np.random.seed(42)
work_path = 'work/model'# AFNONetmodel = AFNONet(num_classes=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0threshold = 0.0best_acc = 0.0val_acc = 0.0loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording lossacc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracyloss_iter = 0acc_iter = 0for epoch in range(n_epochs): # ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy() print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr())) for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = accuracy_manager.compute(logits, labels)
accuracy_manager.update(acc) if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100)) # ---------- Validation ----------
model.eval() for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = val_accuracy_manager.compute(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter) print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100)) # ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
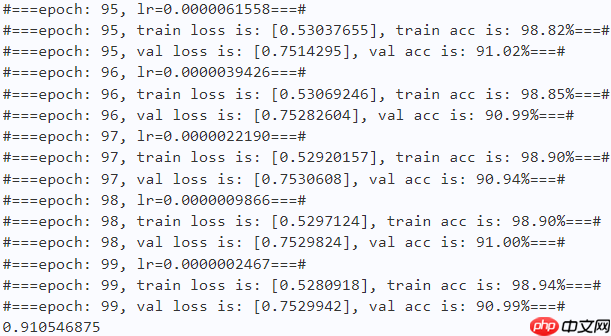
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
2.5 结果分析
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
import time
work_path = 'work/model'model = AFNONet(num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
bb = time.time()print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))
Throughout:608
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [ 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] return [text_labels[int(i)] for i in labels]
def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten() for i, (ax, img) in enumerate(zip(axes, imgs)): if paddle.is_tensor(img):
ax.imshow(img.numpy()) else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False) if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i]) return axes
work_path = 'work/model'X, y = next(iter(DataLoader(val_dataset, batch_size=18))) model = AFNONet(num_classes=10) model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams')) model.set_state_dict(model_state_dict) model.eval() logits = model(X) y_pred = paddle.argmax(logits, -1) X = paddle.transpose(X, [0, 2, 3, 1]) axes = show_images(X.reshape((18, 224, 224, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y)) plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
总结
本文将Transformer与改进的FNO相结合,提出了一种新的频域混合器,为频域Transformer提供了新思路。




























