






本文复现论文提出的MetaHeac模型,基于PaddlePaddle 2.3.0框架,在腾讯Look-alike数据集上进行,解决look-alike建模挑战,复现AUC达0.7112,还介绍了数据集、环境、步骤、代码结构及复现心得。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文复现-MetaHeac
一、简介
在推荐系统和广告平台上,营销人员总是希望通过视频或者社交等媒体渠道向潜在用户推广商品、内容或者广告。扩充候选集技术(Look-alike建模)是一种很有效的解决方案,但look-alike建模通常面临两个挑战:(1)一家公司每天可以开展数百场营销活动,以推广完全不同类别的各种内容。(2)某项活动的种子集只能覆盖有限的用户,因此一个基于有限种子用户的定制化模型往往会产生严重的过拟合。为了解决以上的挑战,论文《Learning to Expand Audience via Meta Hybrid Experts and Critics for Recommendation and Advertising》提出了一种新的两阶段框架Meta Hybrid Experts and Critics (MetaHeac),采用元学习的方法训练一个泛化初始化模型,从而能够快速适应新类别内容推广任务。
MetaHeac训练流程如下: 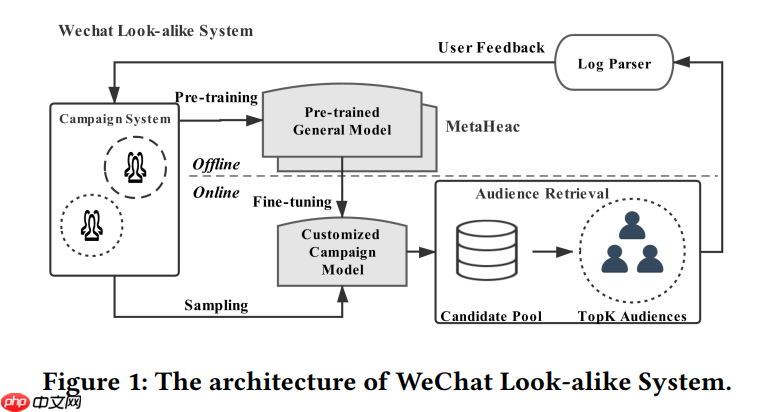
模型核心结构如下: 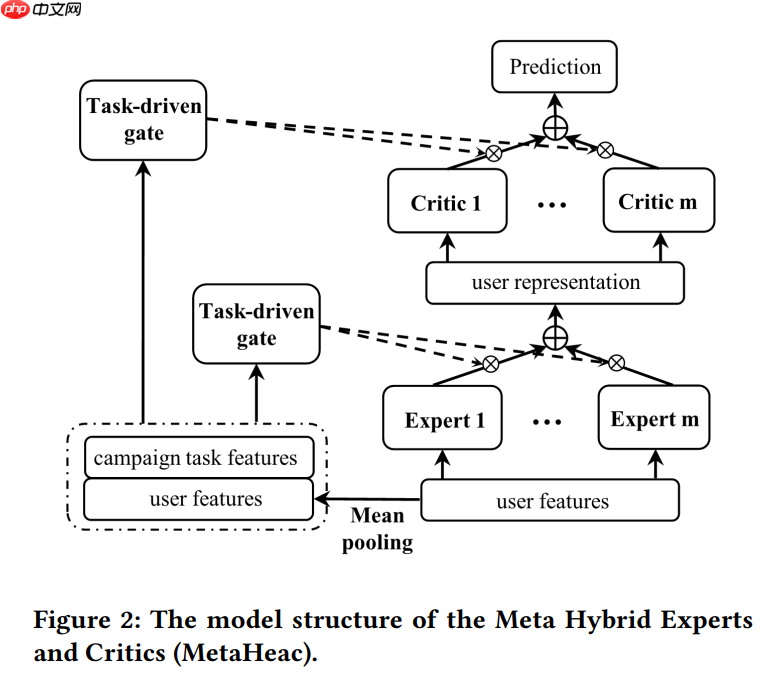
为了复现文献中的实验结果,本项目基于paddlepaddle深度学习框架,并在Lookalike数据集上进行训练和测试。
论文 :
- [1] Yongchun Zhu, Yudan Liu, Ruobing Xie, Fuzhen Zhuang, Xiaobo Hao, Kaikai Ge, Xu Zhang, Leyu Lin, Juan Cao. Learning to Expand Audience via Meta Hybrid Experts and Critics for Recommendation and Advertising
项目参考 : https://github.com/easezyc/MetaHeac
二、复现精度
基于paddlepaddle深度学习框架,对文献MetaHeac进行复现后,测试精度如下表所示。
| 模型 | auc | batch_size | epoch_num | Time of each epoch |
|---|---|---|---|---|
| MetaHeac | 0.7112 | 1024 | 1 | 3个小时左右 |
超参数配置如下表所示:
| 超参数名 | 设置值 |
|---|---|
| batch_size | 1024 |
| task_count | 5 |
| global_learning_rate | 0.001 |
| local_test_learning_rate | 0.001 |
| local_lr | 0.0002 |
三、数据集
本项目使用的是Tencent Look-alike Dataset,该数据集包含几百个种子人群、海量候选人群对应的用户特征,以及种子人群对应的广告特征。出于业务数据安全保证的考虑,所有数据均为脱敏处理后的数据。本次复现使用处理过的数据集,直接下载propocessed data。
数据集链接: https://paddlerec.bj.bcebos.com/datasets/lookalike/Lookalike_data.rar

四、环境依赖
- 硬件:
- x86 cpu
- NVIDIA GPU
- 框架:
- PaddlePaddle == 2.3.0
五、快速开始
# step1: 确认您当前所在目录为PaddleRec/models/multitask/metaheac %cd PaddleRec/models/multitask/metaheac
/home/aistudio/PaddleRec/models/multitask/metaheac
# step2: 进入paddlerec/datasets/目录下,执行该脚本,会从国内源的服务器上下载我们预处理完成的Lookalike全量数据集,并解压到指定文件夹。%cd ../../../datasets/Lookalike !sh run.sh
# step3: train%cd ../../models/multitask/metaheac/ !python -u ../../../tools/trainer.py -m config_big.yaml
# step4: infer 此时test数据集为hot!python -u ./infer_meta.py -m config_big.yaml
# step5:修改config_big.yaml文件中test_data_dir的路径为cold!python -u ./infer_meta.py -m config_big.yaml
config_big.yaml配置文件中参数如下:
| 参数选项 | 默认值 | 说明 |
|---|---|---|
| --batch_size | 1024 | 训练和测试时,一个batch的任务数 |
| --task_count | 5 | 子任务类别数 |
| --global_learning_rate | 0.001 | 全局更新时学习率 |
| local_test_learning_rate | 0.001 | 测试时学习率 |
| local_lr | 0.0002 | 局部更新时学习率 |
| embed_dim | 64 | 嵌入向量的维度 |
| mlp_dims | [64, 64] | 全连接层的维度 |
| num_expert | 8 | 专家数量 |
| num_output | 5 | 批评者数量 |
六、metaheac目录下代码结构与详细说明
├── data #样例数据
├── train #训练数据
├── train_stage1.pkl
├── test #测试数据
├── test_stage1.pkl
├── test_stage2.pkl
├── net.py # 核心模型组网├── config.yaml # sample数据配置├── config_big.yaml # 全量数据配置├── dygraph_model.py # 构建动态图├── reader_train.py # 训练数据读取程序├── reader_test.py # infer数据读取程序├── readme.md #文档
数据集说明
为了测试模型在不同规模的内容定向推广任务上的表现,将数据集根据内容定向推广任务给定的候选集大小进行了划分,分为大于T和小于T两部分。将腾讯广告大赛2018的Look-alike数据集中的T设置为4000,其中hot数据集中候选集大于T,cold数据集中候选集小于T.
infer_meta.py说明
infer_meta.py是用于元学习模型infer的tool,在使用中主要有以下几点需要注意:
- 在对模型进行infer时(train时也可使用这样的操作),可以将runner.infer_batch_size注释掉,这样将禁用DataLoader的自动组batch功能,进而可以使用自定义的组batch方式.
- 由于元学习在infer时需要先对特定任务的少量数据集进行训练,因此在infer_meta.py的infer_dataloader中每次接收单个子任务的全量infer数据集(包括训练数据和测试数据).
- 实际组batch在infer.py中进行,在获取到单个子任务的数据后,获取config中的batch_size参数,对训练数据和测试数据进行组batch,并分别调用dygraph_model.py中的infer_train_forward和infer_forward进行训练和测试.
- 和普通infer不同,由于需要对单个子任务进行少量数据的train和test,对于每个子任务来说加载的都是train阶段训练好的泛化模型.
- 在对单个子任务infer时,创建了局部的paddle.metric.Auc("ROC"),可以查看每个子任务的AUC指标,在全局metric中维护包含所有子任务的AUC指标.
七、复现心得
7.1 模型组网成功,但是精度相差较大
基于论文开源的代码实现基于Paddle的代码还是比较简单的,但是模型组网成功后,精度与原论文精度相差很大。 很可能是模型在前向传播时就已经出现问题了,建议基于官方提供的reprod_log,与参考代码进行一步步的前向对齐,才能保证模型组网万无一失。
7.2 前向传播基本对齐,但是精度达不到
在本项目复现时,遇到最大的问题是前向对齐时的误差很小,但是无论如何第一轮的loss就是对不齐。找了很久问题,最后直接将参考代码的初始化参数加载到paddle复现的模型上,成功跑出了原论文精度,所以如果前向没大问题,也有可能是模型初始化参数的问题,可以设置下随机种子和加载可复现的初始化参数。
7.3 数据读取
由于元学习训练方式与传统训练方式有所区别,所以要单独写train和infer的数据读取。细节部分在infer_meta.py说明中有提到,主要是关掉dataloader默认的组batch方式,自己写组batch。
八、模型信息
| 信息 | 说明 |
|---|---|
| 发布者 | 宁文彬 |
| 时间 | 2022.06 |
| 框架版本 | Paddle 2.3.0 |
| 应用场景 | 元学习 |
| 支持硬件 | GPU、CPU |




























