






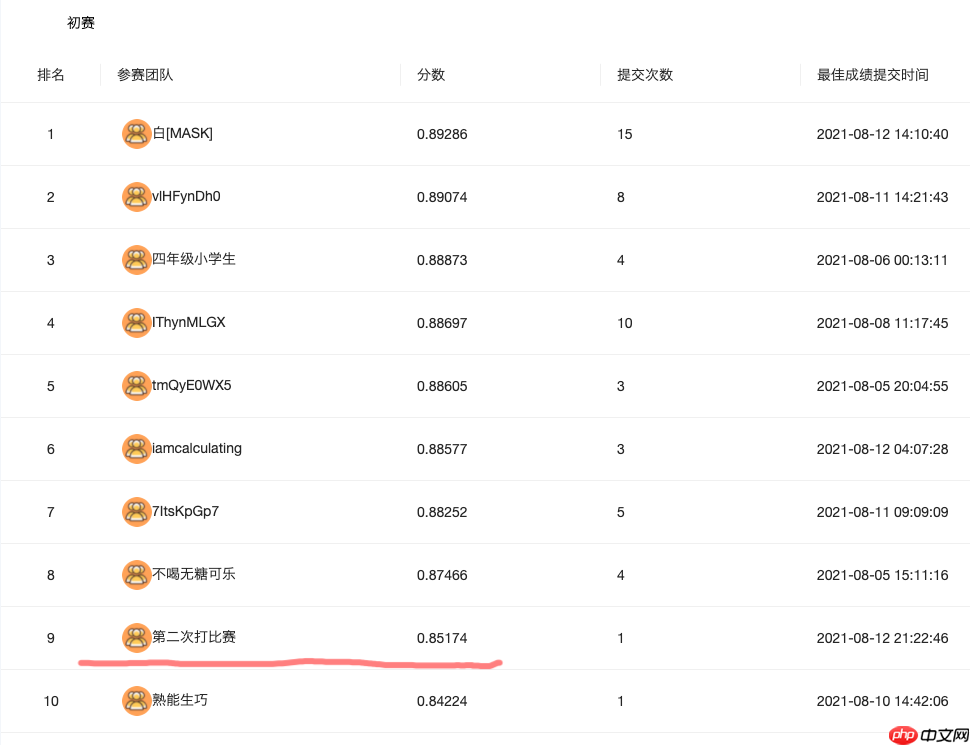
该赛事聚焦医疗资源优化,需依据问诊文本(含年龄段、主诉等)完成10类就诊方向多分类。提供约5000条训练数据与1000余条测试数据,基线用ernie-tiny模型拼接文本微调,线下验证精度超0.98,线上得分0.85174,存在过拟合,可通过换大模型等策略改进。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

赛事背景
人民对于医疗健康的需求在不断增长,但社会现阶段医疗资源紧缺,往往排队一上午看病10分钟,时间和精神成本巨大,如何更好的优化医疗资源配置,找到合适的方向,进行分级诊疗,是当前社会的重要课题。
大众自觉身体状态异常,有时不能准确判断自己是否患有疾病,需要寻求有专业知识的人进行判断,但是主诉者一般进行口语化表述,不容易进行精准高效的指引。
赛事任务
进行简单分诊需要一定的数据和经验知识进行支撑,本次比赛提供了部分好大夫在线的真实问诊数据,经过严格脱敏,提供给参赛者进行多分类任务,具体为通过处理文字诉求,给出10个常见的就诊方向之一。
数据说明
比赛提供约5000条训练数据,1000余条测试数据。
单条数据包含年龄段、主诉、标题、希望获得的帮助和其他描述字段文本,以及就诊方向标签 i∈int [0,9]
评估指标
macro F1-score
思路
典型的文本多分类任务。
将各文本字段按次序拼接后使用预训练模型进行微调。
本 baseline 使用的预训练模型为 ernie-tiny: https://arxiv.org/abs/2106.02241
效果
- 线下验证集(9:1 划分)精度:0.98+
- 线上得分:0.85174
可能的改进策略
本题比较容易过拟合。
- 使用其他较大参数量的模型;
- 使用 FGM 等对抗训练方法;
- 参数、模型修改、scheduler 调优等;
- 数据增广,如拼接变换次序、同义词替换、随机删减等。

In [1]
# 导入必要的库import warnings
warnings.simplefilter('ignore')import numpy as npimport pandas as pd
%matplotlibimport matplotlib.pyplot as pltimport seaborn as snsIn [2]
# 读取数据集train = pd.read_excel('data/data104082/train.xlsx')
test = pd.read_excel('data/data104082/test.xlsx')print(train.shape, test.shape)In [3]
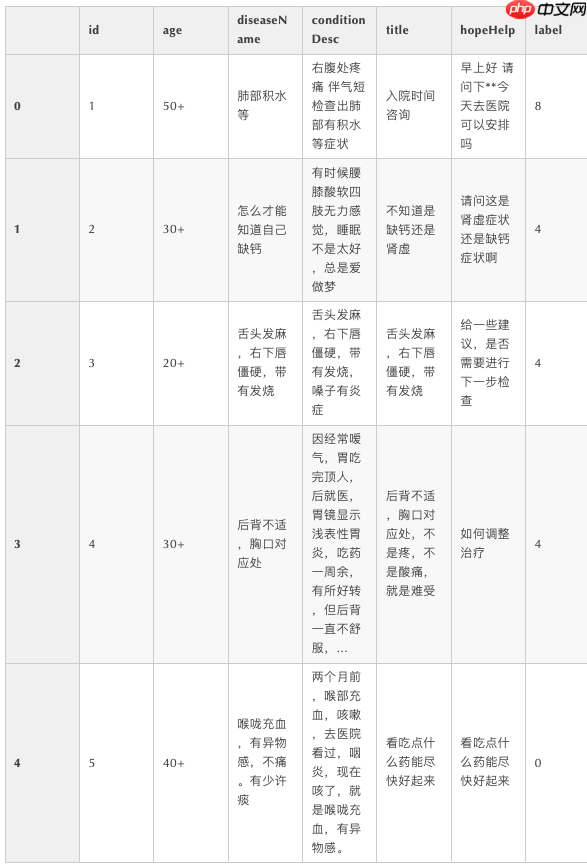
train.head()
In [4]
test.head()
In [5]
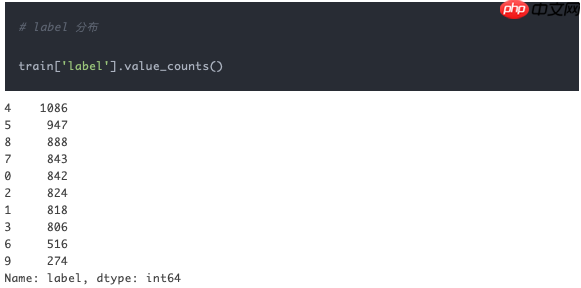
# label 分布train['label'].value_counts()
In [6]
# 空值填充for col in ['diseaseName', 'conditionDesc', 'title', 'hopeHelp']:
train[col].fillna('', inplace=True)
test[col].fillna('', inplace=True)In [7]
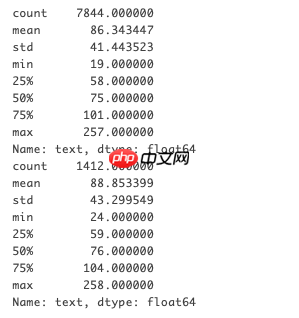
# 文本长度for col in ['diseaseName', 'conditionDesc', 'title', 'hopeHelp']: print(train[col].apply(len).describe()) print(test[col].apply(len).describe())
In [8]
# 清理一些换行字符,不然会对创建数据集有影响def clean_str(x):
return x.replace('\r', '').replace('\t', ' ').replace('\n', ' ')for col in ['diseaseName', 'conditionDesc', 'title', 'hopeHelp']:
train[col] = train[col].apply(lambda x: clean_str(x))
test[col] = test[col].apply(lambda x: clean_str(x))In [9]
# 拼接的长度train['text'] = train['diseaseName'].astype(str) + " " + \
train['conditionDesc'].astype(str) + " " + \
train['title'].astype(str) + " " + \
train['hopeHelp'].astype(str)
test['text'] = test['diseaseName'].astype(str) + " " + \
test['conditionDesc'].astype(str) + " " + \
test['title'].astype(str) + " " + \
test['hopeHelp'].astype(str)print(train['text'].apply(len).describe())print(test['text'].apply(len).describe())看来 max_seq_len 我们使用 256 就可以覆盖所有的样例了
baseline 思路
该题为典型的文本多分类,我们可以先把文本都拼接起来使用 BERT 等预训练模型进行微调建模。
先手动 9:1 切分下训练集,将训练集、验证集和测试集保存为 ChnSentiCorp 格式。
In [10]
train = train[['text', 'label']].copy() test = test[['text']].copy() train = train.sample(frac=1, random_state=42) # 随机打乱train_size = int(0.9 * len(train)) train_df = train[:train_size] valid_df = train[train_size:] test_df = test.copy()print(train_df.shape, valid_df.shape, test_df.shape)
In [11]
# 保存为文本文件train_df[['label', 'text']].to_csv('train.txt', index=False, header=False, sep='\t')
valid_df[['label', 'text']].to_csv('valid.txt', index=False, header=False, sep='\t')自定义数据加载
In [12]
# 更新 paddlehub!pip install -q --upgrade paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple
In [13]
from typing import Dict, List, Optional, Union, Tupleimport paddleimport paddlehub as hubfrom paddlehub.datasets.base_nlp_dataset import TextClassificationDatasetfrom paddlehub.text.bert_tokenizer import BertTokenizerfrom paddlehub.text.tokenizer import CustomTokenizerclass DemoDataset(TextClassificationDataset):
def __init__(self, tokenizer: Union[BertTokenizer, CustomTokenizer], max_seq_len: int = 256, mode: str = 'train'):
base_path = './'
if mode == 'train':
data_file = 'train.txt'
elif mode == 'test':
data_file = 'test.txt'
else:
data_file = 'valid.txt'
super().__init__(
base_path=base_path,
tokenizer=tokenizer,
max_seq_len=max_seq_len,
mode=mode,
data_file=data_file,
label_list=["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"],
is_file_with_header=False)加载预训练模型
我们用 ernie_tiny 模型测试下效果
In [14]
model = hub.Module(name='ernie_tiny', version='2.0.1', task='seq-cls', num_classes=10)
In [15]
# 生成数据集train_dataset = DemoDataset(tokenizer=model.get_tokenizer(), mode='train') valid_dataset = DemoDataset(tokenizer=model.get_tokenizer(), mode='valid')
训练
In [16]
optimizer = paddle.optimizer.AdamW(learning_rate=5e-5, parameters=model.parameters()) trainer = hub.Trainer(model, optimizer, checkpoint_dir='./checkpoint', use_gpu=True)
In [17]
trainer.train(
train_dataset,
epochs=5,
batch_size=32,
eval_dataset=valid_dataset,
save_interval=5,
)预测
In [23]
model = hub.Module(
name='ernie_tiny',
version='2.0.1',
task='seq-cls',
load_checkpoint='./checkpoint/best_model/model.pdparams',
label_map={i:str(i) for i in range(10)}
)In [24]
data = [[i] for i in test_df['text'].values] results = model.predict(data, max_seq_len=256, batch_size=1, use_gpu=False)
In [26]
sub = pd.DataFrame({'id':[i+1 for i in range(len(test_df))], 'label': results})
sub.head()In [27]
sub.to_csv('ernie_tiny_baseline.csv', index=False)提交结果
线上得分: 0.85174
In [ ]




























