






本项目将介绍如何基于PaddleNLP利用ERNIE 3.0预训练模型微调并进行中文情感分析预测。本项目主要包括“什么是情感分析任务”、“ERNIE 3.0模型”、“如何使用ERNIE 3.0中文预训练模型进行句子级别情感分析”等三个部分。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

【快速上手ERNIE 3.0】中文情感分析实战
本项目将介绍如何基于PaddleNLP利用ERNIE 3.0预训练模型微调并进行中文情感分析预测。本项目主要包括“什么是情感分析任务”、“ERNIE 3.0模型”、“如何使用ERNIE 3.0中文预训练模型进行句子级别情感分析”等三个部分。1. 什么是情感分析任务
人类的自然语言蕴含着丰富的情感色彩,语言可以表达情绪(如悲伤、快乐)、心情(如倦怠、忧郁)、喜好(如喜欢、讨厌)、个性特征和立场等等。在互联网大数据时代,人类比以往任何时候都更公开地表达自己的想法和感受,如何快速地监控和理解所有类型数据中情绪变得尤为重要。情感分析是一种自然语言处理 (NLP) 技术,用于确定数据情感是正面的、负面的还是中性的。情感分析通常在文本数据上进行,在商品喜好、消费决策、舆情分析等场景中均有应用。利用机器自动分析这些情感倾向,不但有助于帮助企业监控客户反馈中的品牌和产品情感,并了解客户需求,还有助于企业分析商业伙伴们的态度,以便更好地进行商业决策。
生活中常见将一句话或一段文字的进行情感标记,如标记为正向、负向、中性的三分类问题,这属于句子级别情感分析任务。此外常见的情感分析任务还包括词级别情感分析和目标级别情感分析。

2. ERNIE 3.0模型
ERNIE 3.0首次在百亿级预训练模型中引入大规模知识图谱,提出了海量无监督文本与大规模知识图谱的平行预训练方法(Universal Knowledge-Text Prediction),通过将知识图谱挖掘算法得到五千万知识图谱三元组与4TB大规模语料同时输入到预训练模型中进行联合掩码训练,促进了结构化知识和无结构文本之间的信息共享,大幅提升了模型对于知识的记忆和推理能力。
ERNIE 3.0框架分为两层。第一层是通用语义表示网络,该网络学习数据中的基础和通用的知识。第二层是任务语义表示网络,该网络基于通用语义表示,学习任务相关的知识。在学习过程中,任务语义表示网络只学习对应类别的预训练任务,而通用语义表示网络会学习所有的预训练任务。
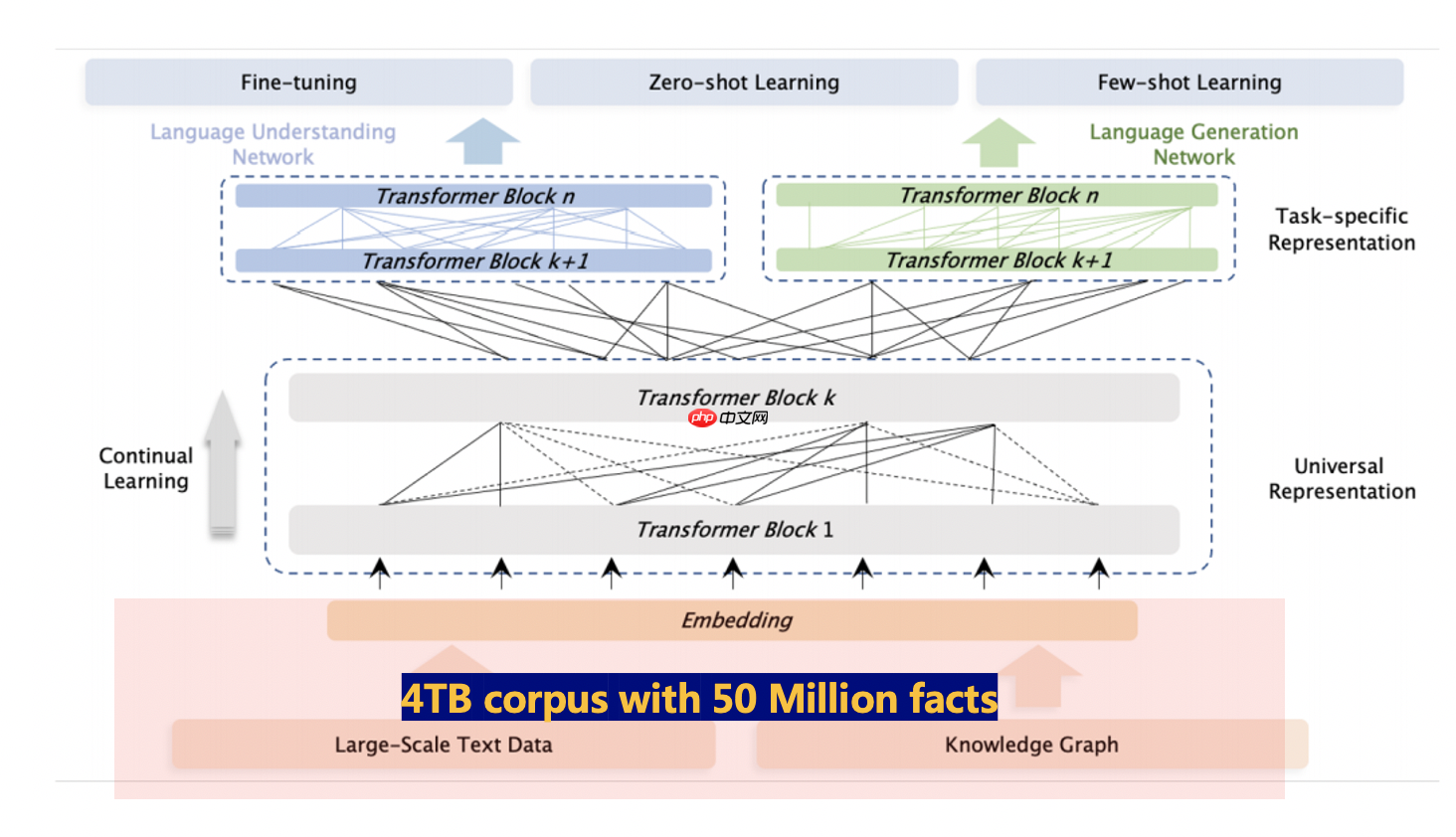
3. 如何使用ERNIE 3.0中文预训练模型进行句子级别情感分析
3.1 环境准备
AI Studio平台默认安装了Paddle和PaddleNLP,并定期更新版本。 如需手动更新Paddle,可参考飞桨安装说明,安装相应环境下最新版飞桨框架。使用如下命令确保安装最新版PaddleNLP:
!pip install --upgrade paddlenlp==2.4.2
import osimport paddleimport paddlenlpprint(paddlenlp.__version__)
2.4.2
3.2 加载中文情感分析数据集ChnSentiCorp
ChnSentiCorp是中文句子级情感分类数据集,包含酒店、笔记本电脑和书籍的网购评论,数据集示例:
qid label text_a 0 1 這間酒店環境和服務態度亦算不錯,但房間空間太小~~不宣容納太大件行李~~且房間格調還可以~~ 中餐廳的廣東點心不太好吃~~要改善之~~~~但算價錢平宜~~可接受~~ 西餐廳格調都很好~~但吃的味道一般且令人等得太耐了~~要改善之~~ 1 <荐书> 推荐所有喜欢<红楼>的红迷们一定要收藏这本书,要知道当年我听说这本书的时候花很长时间去图书馆找和借都没能如愿,所以这次一看到当当有,马上买了,红迷们也要记得备货哦! 2 0 商品的不足暂时还没发现,京东的订单处理速度实在.......周二就打包完成,周五才发货... ...
其中1表示正向情感,0表示负向情感,PaddleNLP已经内置该数据集,一键即可加载。
#加载中文评论情感分析语料数据集ChnSentiCorpfrom paddlenlp.datasets import load_dataset
train_ds, dev_ds, test_ds = load_dataset("chnsenticorp", splits=["train", "dev", "test"])# 数据集返回为MapDataset类型print("数据类型:", type(train_ds))# label代表标签,qid代表数据编号,测试集中不包含标签信息print("训练集样例:", train_ds[0])print("验证集样例:", dev_ds[0])print("测试集样例:", test_ds[0])100%|██████████| 1909/1909 [00:00<00:00, 4265.93it/s]
数据类型:训练集样例: {'text': '选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般', 'label': 1, 'qid': ''} 验证集样例: {'text': '這間酒店環境和服務態度亦算不錯,但房間空間太小~~不宣容納太大件行李~~且房間格調還可以~~ 中餐廳的廣東點心不太好吃~~要改善之~~~~但算價錢平宜~~可接受~~ 西餐廳格調都很好~~但吃的味道一般且令人等得太耐了~~要改善之~~', 'label': 1, 'qid': '0'} 测试集样例: {'text': '这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般', 'label': '', 'qid': '0'}
3.3 加载中文ERNIE 3.0预训练模型和分词器
PaddleNLP中Auto模块(包括AutoModel, AutoTokenizer及各种下游任务类)提供了方便易用的接口,无需指定模型类别,即可调用不同网络结构的预训练模型。PaddleNLP的预训练模型可以很容易地通过from_pretrained()方法加载,Transformer预训练模型汇总包含了40多个主流预训练模型,500多个模型权重。

AutoModelForSequenceClassification可用于句子级情感分析和目标级情感分析任务,通过预训练模型获取输入文本的表示,之后将文本表示进行分类。PaddleNLP已经实现了ERNIE 3.0预训练模型,可以通过一行代码实现ERNIE 3.0预训练模型和分词器的加载。
from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer model_name = "ernie-3.0-medium-zh"model = AutoModelForSequenceClassification.from_pretrained(model_name, num_classes=len(train_ds.label_list)) tokenizer = AutoTokenizer.from_pretrained(model_name)
[2024-08-16 11:53:53,508] [ INFO] - We are usingto load 'ernie-3.0-medium-zh'. [2024-08-16 11:53:53,513] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/transformers/ernie_3.0/ernie_3.0_medium_zh.pdparams and saved to /home/aistudio/.paddlenlp/models/ernie-3.0-medium-zh [2024-08-16 11:53:53,516] [ INFO] - Downloading ernie_3.0_medium_zh.pdparams from https://bj.bcebos.com/paddlenlp/models/transformers/ernie_3.0/ernie_3.0_medium_zh.pdparams 100%|██████████| 313M/313M [00:08<00:00, 40.2MB/s] W0816 11:54:01.802002 580 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 12.0, Runtime API Version: 11.2 W0816 11:54:01.809803 580 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2. [2024-08-16 11:54:06,339] [ INFO] - We are using to load 'ernie-3.0-medium-zh'. [2024-08-16 11:54:06,342] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/transformers/ernie_3.0/ernie_3.0_medium_zh_vocab.txt and saved to /home/aistudio/.paddlenlp/models/ernie-3.0-medium-zh [2024-08-16 11:54:06,345] [ INFO] - Downloading ernie_3.0_medium_zh_vocab.txt from https://bj.bcebos.com/paddlenlp/models/transformers/ernie_3.0/ernie_3.0_medium_zh_vocab.txt 100%|██████████| 182k/182k [00:00<00:00, 12.2MB/s] [2024-08-16 11:54:06,467] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/ernie-3.0-medium-zh/tokenizer_config.json [2024-08-16 11:54:06,470] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/ernie-3.0-medium-zh/special_tokens_map.json
3.4 基于预训练模型的数据处理
Dataset中通常为原始数据,需要经过一定的数据处理并进行采样组batch。
- 通过Dataset的map函数,使用分词器将数据集从原始文本处理成模型的输入。
- 定义paddle.io.BatchSampler和collate_fn构建 paddle.io.DataLoader。
实际训练中,根据显存大小调整批大小batch_size和文本最大长度max_seq_length。
import functoolsimport numpy as npfrom paddle.io import DataLoader, BatchSamplerfrom paddlenlp.data import DataCollatorWithPadding# 数据预处理函数,利用分词器将文本转化为整数序列def preprocess_function(examples, tokenizer, max_seq_length, is_test=False):
result = tokenizer(text=examples["text"], max_seq_len=max_seq_length) if not is_test:
result["labels"] = examples["label"] return result
trans_func = functools.partial(preprocess_function, tokenizer=tokenizer, max_seq_length=128)
train_ds = train_ds.map(trans_func)
dev_ds = dev_ds.map(trans_func)# collate_fn函数构造,将不同长度序列充到批中数据的最大长度,再将数据堆叠collate_fn = DataCollatorWithPadding(tokenizer)# 定义BatchSampler,选择批大小和是否随机乱序,进行DataLoadertrain_batch_sampler = BatchSampler(train_ds, batch_size=32, shuffle=True)
dev_batch_sampler = BatchSampler(dev_ds, batch_size=64, shuffle=False)
train_data_loader = DataLoader(dataset=train_ds, batch_sampler=train_batch_sampler, collate_fn=collate_fn)
dev_data_loader = DataLoader(dataset=dev_ds, batch_sampler=dev_batch_sampler, collate_fn=collate_fn)3.5 数据训练和评估
定义训练所需的优化器、损失函数、评价指标等,就可以开始进行预模型微调任务。
# Adam优化器、交叉熵损失函数、accuracy评价指标optimizer = paddle.optimizer.AdamW(learning_rate=2e-5, parameters=model.parameters()) criterion = paddle.nn.loss.CrossEntropyLoss() metric = paddle.metric.Accuracy()
# 开始训练import timeimport paddle.nn.functional as Ffrom eval import evaluate
epochs = 5 # 训练轮次ckpt_dir = "ernie_ckpt" #训练过程中保存模型参数的文件夹best_acc = 0best_step = 0global_step = 0 #迭代次数tic_train = time.time()for epoch in range(1, epochs + 1): for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch['input_ids'], batch['token_type_ids'], batch['labels'] # 计算模型输出、损失函数值、分类概率值、准确率
logits = model(input_ids, token_type_ids)
loss = criterion(logits, labels)
probs = F.softmax(logits, axis=1)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate() # 每迭代10次,打印损失函数值、准确率、计算速度
global_step += 1
if global_step % 10 == 0: print( "global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc, 10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad() # 每迭代100次,评估当前训练的模型、保存当前模型参数和分词器的词表等
if global_step % 100 == 0:
save_dir = ckpt_dir if not os.path.exists(save_dir):
os.makedirs(save_dir) print(global_step, end=' ')
acc_eval = evaluate(model, criterion, metric, dev_data_loader) if acc_eval > best_acc:
best_acc = acc_eval
best_step = global_step
model.save_pretrained(save_dir)
tokenizer.save_pretrained(save_dir)global step 10, epoch: 1, batch: 10, loss: 0.48336, accu: 0.67812, speed: 3.48 step/s global step 20, epoch: 1, batch: 20, loss: 0.22908, accu: 0.73906, speed: 7.31 step/s global step 30, epoch: 1, batch: 30, loss: 0.43386, accu: 0.77917, speed: 7.59 step/s global step 40, epoch: 1, batch: 40, loss: 0.43480, accu: 0.80234, speed: 7.16 step/s global step 50, epoch: 1, batch: 50, loss: 0.42323, accu: 0.81937, speed: 7.10 step/s global step 60, epoch: 1, batch: 60, loss: 0.47626, accu: 0.82969, speed: 7.09 step/s global step 70, epoch: 1, batch: 70, loss: 0.23110, accu: 0.83616, speed: 7.27 step/s global step 80, epoch: 1, batch: 80, loss: 0.24500, accu: 0.84688, speed: 7.19 step/s global step 90, epoch: 1, batch: 90, loss: 0.37757, accu: 0.85208, speed: 7.45 step/s global step 100, epoch: 1, batch: 100, loss: 0.25137, accu: 0.85562, speed: 6.81 step/s 100 eval loss: 0.26319, accuracy: 0.89250
[2024-08-16 11:56:16,206] [ INFO] - tokenizer config file saved in ernie_ckpt/tokenizer_config.json [2024-08-16 11:56:16,513] [ INFO] - Special tokens file saved in ernie_ckpt/special_tokens_map.json
global step 110, epoch: 1, batch: 110, loss: 0.13416, accu: 0.91563, speed: 1.12 step/s global step 120, epoch: 1, batch: 120, loss: 0.28711, accu: 0.89531, speed: 7.30 step/s global step 130, epoch: 1, batch: 130, loss: 0.27579, accu: 0.90000, speed: 6.65 step/s global step 140, epoch: 1, batch: 140, loss: 0.16122, accu: 0.90781, speed: 7.49 step/s global step 150, epoch: 1, batch: 150, loss: 0.40162, accu: 0.90438, speed: 6.37 step/s global step 160, epoch: 1, batch: 160, loss: 0.22731, accu: 0.90260, speed: 6.96 step/s global step 170, epoch: 1, batch: 170, loss: 0.16370, accu: 0.89955, speed: 7.00 step/s global step 180, epoch: 1, batch: 180, loss: 0.19200, accu: 0.89805, speed: 7.53 step/s global step 190, epoch: 1, batch: 190, loss: 0.21583, accu: 0.89687, speed: 7.72 step/s global step 200, epoch: 1, batch: 200, loss: 0.23488, accu: 0.89906, speed: 7.11 step/s 200 eval loss: 0.23760, accuracy: 0.90583
[2024-08-16 11:56:38,071] [ INFO] - tokenizer config file saved in ernie_ckpt/tokenizer_config.json [2024-08-16 11:56:38,075] [ INFO] - Special tokens file saved in ernie_ckpt/special_tokens_map.json
global step 210, epoch: 1, batch: 210, loss: 0.34528, accu: 0.93437, speed: 1.12 step/s global step 220, epoch: 1, batch: 220, loss: 0.27434, accu: 0.92188, speed: 7.29 step/s global step 230, epoch: 1, batch: 230, loss: 0.20707, accu: 0.92500, speed: 6.90 step/s global step 240, epoch: 1, batch: 240, loss: 0.10759, accu: 0.92422, speed: 7.05 step/s global step 250, epoch: 1, batch: 250, loss: 0.12666, accu: 0.92625, speed: 7.00 step/s global step 260, epoch: 1, batch: 260, loss: 0.24930, accu: 0.92656, speed: 7.39 step/s global step 270, epoch: 1, batch: 270, loss: 0.13479, accu: 0.92188, speed: 6.90 step/s global step 280, epoch: 1, batch: 280, loss: 0.24896, accu: 0.92148, speed: 7.12 step/s global step 290, epoch: 1, batch: 290, loss: 0.22099, accu: 0.92153, speed: 7.68 step/s global step 300, epoch: 1, batch: 300, loss: 0.19428, accu: 0.92219, speed: 8.24 step/s 300 eval loss: 0.22168, accuracy: 0.91583
[2024-08-16 11:56:59,754] [ INFO] - tokenizer config file saved in ernie_ckpt/tokenizer_config.json [2024-08-16 11:56:59,759] [ INFO] - Special tokens file saved in ernie_ckpt/special_tokens_map.json
global step 310, epoch: 2, batch: 10, loss: 0.18281, accu: 0.90312, speed: 1.04 step/s global step 320, epoch: 2, batch: 20, loss: 0.12715, accu: 0.92188, speed: 6.62 step/s global step 330, epoch: 2, batch: 30, loss: 0.33233, accu: 0.92708, speed: 6.91 step/s global step 340, epoch: 2, batch: 40, loss: 0.13222, accu: 0.92578, speed: 6.67 step/s global step 350, epoch: 2, batch: 50, loss: 0.16470, accu: 0.92875, speed: 7.26 step/s global step 360, epoch: 2, batch: 60, loss: 0.23461, accu: 0.93281, speed: 6.66 step/s global step 370, epoch: 2, batch: 70, loss: 0.25790, accu: 0.93527, speed: 7.26 step/s global step 380, epoch: 2, batch: 80, loss: 0.14061, accu: 0.93867, speed: 6.75 step/s global step 390, epoch: 2, batch: 90, loss: 0.16339, accu: 0.93715, speed: 6.72 step/s global step 400, epoch: 2, batch: 100, loss: 0.09874, accu: 0.94031, speed: 7.20 step/s 400 eval loss: 0.21534, accuracy: 0.91917
[2024-08-16 11:57:21,502] [ INFO] - tokenizer config file saved in ernie_ckpt/tokenizer_config.json [2024-08-16 11:57:21,505] [ INFO] - Special tokens file saved in ernie_ckpt/special_tokens_map.json
global step 410, epoch: 2, batch: 110, loss: 0.07595, accu: 0.95000, speed: 1.21 step/s global step 420, epoch: 2, batch: 120, loss: 0.20956, accu: 0.94531, speed: 7.41 step/s global step 430, epoch: 2, batch: 130, loss: 0.09274, accu: 0.94688, speed: 7.26 step/s global step 440, epoch: 2, batch: 140, loss: 0.14690, accu: 0.94766, speed: 7.09 step/s global step 450, epoch: 2, batch: 150, loss: 0.27569, accu: 0.94500, speed: 6.95 step/s global step 460, epoch: 2, batch: 160, loss: 0.31928, accu: 0.94271, speed: 7.09 step/s global step 470, epoch: 2, batch: 170, loss: 0.13881, accu: 0.93973, speed: 7.13 step/s global step 480, epoch: 2, batch: 180, loss: 0.06345, accu: 0.94180, speed: 7.48 step/s global step 490, epoch: 2, batch: 190, loss: 0.21738, accu: 0.94375, speed: 7.42 step/s global step 500, epoch: 2, batch: 200, loss: 0.19904, accu: 0.94406, speed: 7.27 step/s 500 eval loss: 0.19972, accuracy: 0.93000
[2024-08-16 11:57:42,695] [ INFO] - tokenizer config file saved in ernie_ckpt/tokenizer_config.json [2024-08-16 11:57:42,700] [ INFO] - Special tokens file saved in ernie_ckpt/special_tokens_map.json
global step 510, epoch: 2, batch: 210, loss: 0.26500, accu: 0.94375, speed: 1.16 step/s global step 520, epoch: 2, batch: 220, loss: 0.06174, accu: 0.93906, speed: 6.83 step/s global step 530, epoch: 2, batch: 230, loss: 0.04950, accu: 0.94479, speed: 7.50 step/s global step 540, epoch: 2, batch: 240, loss: 0.17884, accu: 0.94453, speed: 6.89 step/s global step 550, epoch: 2, batch: 250, loss: 0.20181, accu: 0.94375, speed: 6.96 step/s global step 560, epoch: 2, batch: 260, loss: 0.02750, accu: 0.94375, speed: 7.33 step/s global step 570, epoch: 2, batch: 270, loss: 0.06160, accu: 0.93929, speed: 7.41 step/s global step 580, epoch: 2, batch: 280, loss: 0.16172, accu: 0.94023, speed: 6.86 step/s global step 590, epoch: 2, batch: 290, loss: 0.31605, accu: 0.94201, speed: 7.21 step/s global step 600, epoch: 2, batch: 300, loss: 0.37462, accu: 0.94219, speed: 8.23 step/s 600 eval loss: 0.18575, accuracy: 0.92833 global step 610, epoch: 3, batch: 10, loss: 0.19020, accu: 0.95625, speed: 1.63 step/s global step 620, epoch: 3, batch: 20, loss: 0.04493, accu: 0.96719, speed: 7.63 step/s global step 630, epoch: 3, batch: 30, loss: 0.01316, accu: 0.96771, speed: 7.32 step/s global step 640, epoch: 3, batch: 40, loss: 0.04468, accu: 0.97266, speed: 7.61 step/s global step 650, epoch: 3, batch: 50, loss: 0.17604, accu: 0.97125, speed: 7.15 step/s global step 660, epoch: 3, batch: 60, loss: 0.03763, accu: 0.97031, speed: 7.22 step/s global step 670, epoch: 3, batch: 70, loss: 0.28883, accu: 0.96920, speed: 7.53 step/s global step 680, epoch: 3, batch: 80, loss: 0.12117, accu: 0.96875, speed: 7.29 step/s global step 690, epoch: 3, batch: 90, loss: 0.01267, accu: 0.96875, speed: 7.04 step/s global step 700, epoch: 3, batch: 100, loss: 0.10047, accu: 0.96813, speed: 6.55 step/s 700 eval loss: 0.21618, accuracy: 0.93667
[2024-08-16 11:58:22,368] [ INFO] - tokenizer config file saved in ernie_ckpt/tokenizer_config.json [2024-08-16 11:58:22,378] [ INFO] - Special tokens file saved in ernie_ckpt/special_tokens_map.json
global step 710, epoch: 3, batch: 110, loss: 0.10897, accu: 0.95000, speed: 1.15 step/s global step 720, epoch: 3, batch: 120, loss: 0.03770, accu: 0.96719, speed: 7.31 step/s global step 730, epoch: 3, batch: 130, loss: 0.06193, accu: 0.96250, speed: 7.34 step/s global step 740, epoch: 3, batch: 140, loss: 0.09251, accu: 0.96094, speed: 7.75 step/s global step 750, epoch: 3, batch: 150, loss: 0.04879, accu: 0.96188, speed: 7.59 step/s global step 760, epoch: 3, batch: 160, loss: 0.14314, accu: 0.96562, speed: 7.45 step/s global step 770, epoch: 3, batch: 170, loss: 0.22586, accu: 0.96518, speed: 7.60 step/s global step 780, epoch: 3, batch: 180, loss: 0.12668, accu: 0.96680, speed: 7.68 step/s global step 790, epoch: 3, batch: 190, loss: 0.32640, accu: 0.96771, speed: 7.74 step/s global step 800, epoch: 3, batch: 200, loss: 0.04094, accu: 0.96844, speed: 7.02 step/s 800 eval loss: 0.22617, accuracy: 0.92167 global step 810, epoch: 3, batch: 210, loss: 0.14320, accu: 0.97813, speed: 1.77 step/s global step 820, epoch: 3, batch: 220, loss: 0.09210, accu: 0.97656, speed: 7.32 step/s global step 830, epoch: 3, batch: 230, loss: 0.06111, accu: 0.97396, speed: 6.92 step/s global step 840, epoch: 3, batch: 240, loss: 0.20377, accu: 0.97344, speed: 6.65 step/s global step 850, epoch: 3, batch: 250, loss: 0.04668, accu: 0.96937, speed: 7.81 step/s global step 860, epoch: 3, batch: 260, loss: 0.05583, accu: 0.96823, speed: 7.56 step/s global step 870, epoch: 3, batch: 270, loss: 0.16349, accu: 0.97009, speed: 7.97 step/s global step 880, epoch: 3, batch: 280, loss: 0.05248, accu: 0.96992, speed: 6.92 step/s global step 890, epoch: 3, batch: 290, loss: 0.08077, accu: 0.96910, speed: 7.31 step/s global step 900, epoch: 3, batch: 300, loss: 0.01152, accu: 0.96937, speed: 8.23 step/s 900 eval loss: 0.21173, accuracy: 0.93333 global step 910, epoch: 4, batch: 10, loss: 0.01062, accu: 0.97188, speed: 1.59 step/s global step 920, epoch: 4, batch: 20, loss: 0.03939, accu: 0.97969, speed: 7.09 step/s global step 930, epoch: 4, batch: 30, loss: 0.03197, accu: 0.98125, speed: 7.12 step/s global step 940, epoch: 4, batch: 40, loss: 0.06251, accu: 0.97891, speed: 7.26 step/s global step 950, epoch: 4, batch: 50, loss: 0.01186, accu: 0.98062, speed: 7.56 step/s global step 960, epoch: 4, batch: 60, loss: 0.07177, accu: 0.98177, speed: 7.44 step/s global step 970, epoch: 4, batch: 70, loss: 0.06624, accu: 0.98259, speed: 7.71 step/s global step 980, epoch: 4, batch: 80, loss: 0.05749, accu: 0.98281, speed: 7.37 step/s global step 990, epoch: 4, batch: 90, loss: 0.01877, accu: 0.98229, speed: 7.28 step/s global step 1000, epoch: 4, batch: 100, loss: 0.00847, accu: 0.98188, speed: 7.45 step/s 1000 eval loss: 0.27880, accuracy: 0.92500 global step 1010, epoch: 4, batch: 110, loss: 0.01910, accu: 0.96562, speed: 1.78 step/s global step 1020, epoch: 4, batch: 120, loss: 0.14394, accu: 0.96250, speed: 7.28 step/s global step 1030, epoch: 4, batch: 130, loss: 0.01614, accu: 0.97083, speed: 7.62 step/s global step 1040, epoch: 4, batch: 140, loss: 0.30530, accu: 0.96719, speed: 7.37 step/s global step 1050, epoch: 4, batch: 150, loss: 0.01184, accu: 0.96813, speed: 7.54 step/s global step 1060, epoch: 4, batch: 160, loss: 0.06261, accu: 0.97031, speed: 7.64 step/s global step 1070, epoch: 4, batch: 170, loss: 0.00897, accu: 0.97277, speed: 7.47 step/s global step 1080, epoch: 4, batch: 180, loss: 0.01031, accu: 0.97422, speed: 7.67 step/s global step 1090, epoch: 4, batch: 190, loss: 0.15139, accu: 0.97396, speed: 7.75 step/s global step 1100, epoch: 4, batch: 200, loss: 0.00472, accu: 0.97656, speed: 7.35 step/s 1100 eval loss: 0.21473, accuracy: 0.93500 global step 1110, epoch: 4, batch: 210, loss: 0.14274, accu: 0.99375, speed: 1.80 step/s global step 1120, epoch: 4, batch: 220, loss: 0.14070, accu: 0.98438, speed: 7.76 step/s global step 1130, epoch: 4, batch: 230, loss: 0.03954, accu: 0.98542, speed: 7.77 step/s global step 1140, epoch: 4, batch: 240, loss: 0.23632, accu: 0.98281, speed: 7.67 step/s global step 1150, epoch: 4, batch: 250, loss: 0.01650, accu: 0.98313, speed: 7.41 step/s global step 1160, epoch: 4, batch: 260, loss: 0.01198, accu: 0.98281, speed: 7.84 step/s global step 1170, epoch: 4, batch: 270, loss: 0.01533, accu: 0.98304, speed: 6.81 step/s global step 1180, epoch: 4, batch: 280, loss: 0.00663, accu: 0.98164, speed: 7.19 step/s global step 1190, epoch: 4, batch: 290, loss: 0.03840, accu: 0.98090, speed: 7.61 step/s global step 1200, epoch: 4, batch: 300, loss: 0.21318, accu: 0.98094, speed: 8.51 step/s 1200 eval loss: 0.27002, accuracy: 0.92083 global step 1210, epoch: 5, batch: 10, loss: 0.01843, accu: 0.98125, speed: 1.66 step/s global step 1220, epoch: 5, batch: 20, loss: 0.03889, accu: 0.98594, speed: 7.00 step/s global step 1230, epoch: 5, batch: 30, loss: 0.02858, accu: 0.98438, speed: 7.30 step/s global step 1241240, epoch: 5, batch: 40, loss: 0.01512, accu: 0.98516, speed: 7.19 step/s global step 1250, epoch: 5, batch: 50, loss: 0.01569, accu: 0.98438, speed: 7.58 step/s global step 1260, epoch: 5, batch: 60, loss: 0.01742, accu: 0.98385, speed: 7.41 step/s global step 1270, epoch: 5, batch: 70, loss: 0.02197, accu: 0.98438, speed: 7.26 step/s global step 1280, epoch: 5, batch: 80, loss: 0.00295, accu: 0.98516, speed: 7.76 step/s global step 1290, epoch: 5, batch: 90, loss: 0.03937, accu: 0.98438, speed: 7.79 step/s global step 1300, epoch: 5, batch: 100, loss: 0.08068, accu: 0.98438, speed: 7.17 step/s 1300 eval loss: 0.25191, accuracy: 0.93583 global step 1310, epoch: 5, batch: 110, loss: 0.00238, accu: 0.99062, speed: 1.78 step/s global step 1320, epoch: 5, batch: 120, loss: 0.05467, accu: 0.99219, speed: 7.38 step/s global step 1330, epoch: 5, batch: 130, loss: 0.00909, accu: 0.98750, speed: 7.74 step/s global step 1340, epoch: 5, batch: 140, loss: 0.06977, accu: 0.98594, speed: 7.52 step/s global step 1350, epoch: 5, batch: 150, loss: 0.01160, accu: 0.98250, speed: 7.56 step/s global step 1360, epoch: 5, batch: 160, loss: 0.15503, accu: 0.98125, speed: 7.56 step/s global step 1370, epoch: 5, batch: 170, loss: 0.17211, accu: 0.98036, speed: 7.61 step/s global step 1380, epoch: 5, batch: 180, loss: 0.13631, accu: 0.98086, speed: 7.44 step/s global step 1390, epoch: 5, batch: 190, loss: 0.12389, accu: 0.98056, speed: 7.59 step/s global step 1400, epoch: 5, batch: 200, loss: 0.00964, accu: 0.97844, speed: 7.82 step/s 1400 eval loss: 0.25752, accuracy: 0.93083 global step 1410, epoch: 5, batch: 210, loss: 0.27650, accu: 0.96250, speed: 1.78 step/s global step 1420, epoch: 5, batch: 220, loss: 0.07868, accu: 0.97500, speed: 7.62 step/s global step 1430, epoch: 5, batch: 230, loss: 0.14357, accu: 0.97188, speed: 7.87 step/s global step 1440, epoch: 5, batch: 240, loss: 0.13951, accu: 0.97188, speed: 7.55 step/s global step 1450, epoch: 5, batch: 250, loss: 0.13889, accu: 0.96937, speed: 7.39 step/s global step 1460, epoch: 5, batch: 260, loss: 0.04986, accu: 0.97083, speed: 7.53 step/s global step 1470, epoch: 5, batch: 270, loss: 0.00908, accu: 0.97366, speed: 7.73 step/s global step 1480, epoch: 5, batch: 280, loss: 0.02084, accu: 0.97383, speed: 7.29 step/s global step 1490, epoch: 5, batch: 290, loss: 0.03722, accu: 0.97465, speed: 7.43 step/s global step 1500, epoch: 5, batch: 300, loss: 0.08914, accu: 0.97562, speed: 8.38 step/s 1500 eval loss: 0.22913, accuracy: 0.92667
模型训练过程中会输出如下日志:
global step 10, epoch: 1, batch: 10, loss: 0.66181, accu: 0.55000, speed: 4.53 step/sglobal step 20, epoch: 1, batch: 20, loss: 0.54043, accu: 0.60938, speed: 4.92 step/sglobal step 30, epoch: 1, batch: 30, loss: 0.42240, accu: 0.67708, speed: 4.88 step/sglobal step 40, epoch: 1, batch: 40, loss: 0.34822, accu: 0.72266, speed: 4.86 step/sglobal step 50, epoch: 1, batch: 50, loss: 0.31792, accu: 0.74438, speed: 4.85 step/sglobal step 60, epoch: 1, batch: 60, loss: 0.36544, accu: 0.76719, speed: 4.86 step/sglobal step 70, epoch: 1, batch: 70, loss: 0.19064, accu: 0.78795, speed: 4.87 step/sglobal step 80, epoch: 1, batch: 80, loss: 0.32033, accu: 0.79883, speed: 4.86 step/sglobal step 90, epoch: 1, batch: 90, loss: 0.22526, accu: 0.81007, speed: 4.82 step/sglobal step 100, epoch: 1, batch: 100, loss: 0.30424, accu: 0.81781, speed: 4.85 step/s100 eval loss: 0.25176, accuracy: 0.91167[2022-05-13 17:07:09,935] [ INFO] - tokenizer config file saved in ernie_ckpt_1/tokenizer_config.json [2022-05-13 17:07:09,938] [ INFO] - Special tokens file saved in ernie_ckpt_1/special_tokens_map.json ...
训练5个epoch预计需要7分钟。
from eval import evaluate# 加载ERNIR 3.0最佳模型参数params_path = 'ernie_ckpt/model_state.pdparams'state_dict = paddle.load(params_path)
model.set_dict(state_dict)# 也可以选择加载预先训练好的模型参数结果查看模型训练结果# model.set_dict(paddle.load('ernie_ckpt_trained/model_state.pdparams'))print('ERNIE 3.0-Medium 在ChnSentiCorp的dev集表现', end=' ')
eval_acc = evaluate(model, criterion, metric, dev_data_loader)ERNIE 3.0-Medium 在ChnSentiCorp的dev集表现 eval loss: 0.21618, accuracy: 0.93667
3.6 情感分析结果预测与保存
加载微调好的模型参数进行情感分析预测,并保存预测结果
# 测试集数据预处理,利用分词器将文本转化为整数序列trans_func_test = functools.partial(preprocess_function, tokenizer=tokenizer, max_seq_length=128, is_test=True) test_ds_trans = test_ds.map(trans_func_test)# 进行采样组batchcollate_fn_test = DataCollatorWithPadding(tokenizer) test_batch_sampler = BatchSampler(test_ds_trans, batch_size=32, shuffle=False) test_data_loader = DataLoader(dataset=test_ds_trans, batch_sampler=test_batch_sampler, collate_fn=collate_fn_test)
# 模型预测分类结果import paddle.nn.functional as F
label_map = {0: '负面', 1: '正面'}
results = []
model.eval()for batch in test_data_loader:
input_ids, token_type_ids = batch['input_ids'], batch['token_type_ids']
logits = model(batch['input_ids'], batch['token_type_ids'])
probs = F.softmax(logits, axis=-1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
preds = [label_map[i] for i in idx]
results.extend(preds)# 存储ChnSentiCorp预测结果 test_ds = load_dataset("chnsenticorp", splits=["test"])
res_dir = "./results"if not os.path.exists(res_dir):
os.makedirs(res_dir)with open(os.path.join(res_dir, "ChnSentiCorp.tsv"), 'w', encoding="utf8") as f:
f.write("qid\ttext\tprediction\n") for i, pred in enumerate(results):
f.write(test_ds[i]['qid']+"\t"+test_ds[i]['text']+"\t"+pred+"\n")ChnSentiCorp预测结果示例:





























