






随着人工智能日新月异的发展,其作为一个新行业吸引了众多的同学们进行学习,但是各种各样的网络技巧层出不穷,为同学们的学习无形之中添加了很多难度。所以,针对CNN的各个部分我整理出这样一份综述性技术手册,包含对与Tricks的主要思想介绍以及对应的paddle代码实现,对于大部分已经入门计算机视觉的同学来说,这应该是一份较好的进阶手册,从某些方面来说,也能够有效的启发研究思路。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

【CNN Tricks 不完全指北手册】基于飞桨来看CNN各个部分的提升技巧
0、引言
随着人工智能日新月异的发展,其作为一个新行业吸引了众多的同学们进行学习,但是各种各样的网络技巧层出不穷,为同学们的学习无形之中添加了很多难度。所以,针对CNN的各个部分我整理出这样一份综述性技术手册,包含对与Tricks的主要思想介绍以及对应的paddle代码实现,对于大部分已经入门计算机视觉的同学来说,这应该是一份较好的进阶手册,从某些方面来说,也能够有效的启发研究思路。
首先,我将本文定义为技术手册,所以会包含主要的Paddle实现代码,在对应的链接里会包含有一些简单的验证实验和对应的总结,这些总结都是我的一家之言,不能代表该Trick在所有模型结构上的表现,最后,因为目前深度学习技术发展较快,几乎每天都会有新的思想出现,所以是一个不完全技术手册。
从经典的CNN结构来看,CNN主要包含卷积与池化两个部分,那么大部分的模型技巧也会围绕这两个操作进行;其次,针对模型的其他细节部分,例如激活函数、模型的训练、模型的整体结构,都存在一些提升的技巧,这些技巧再结合上模型的整体结构,就会产生一些有趣的Tricks。
1、卷积操作部分
1.1 去除特征图中的冗余:SPConv论文复现
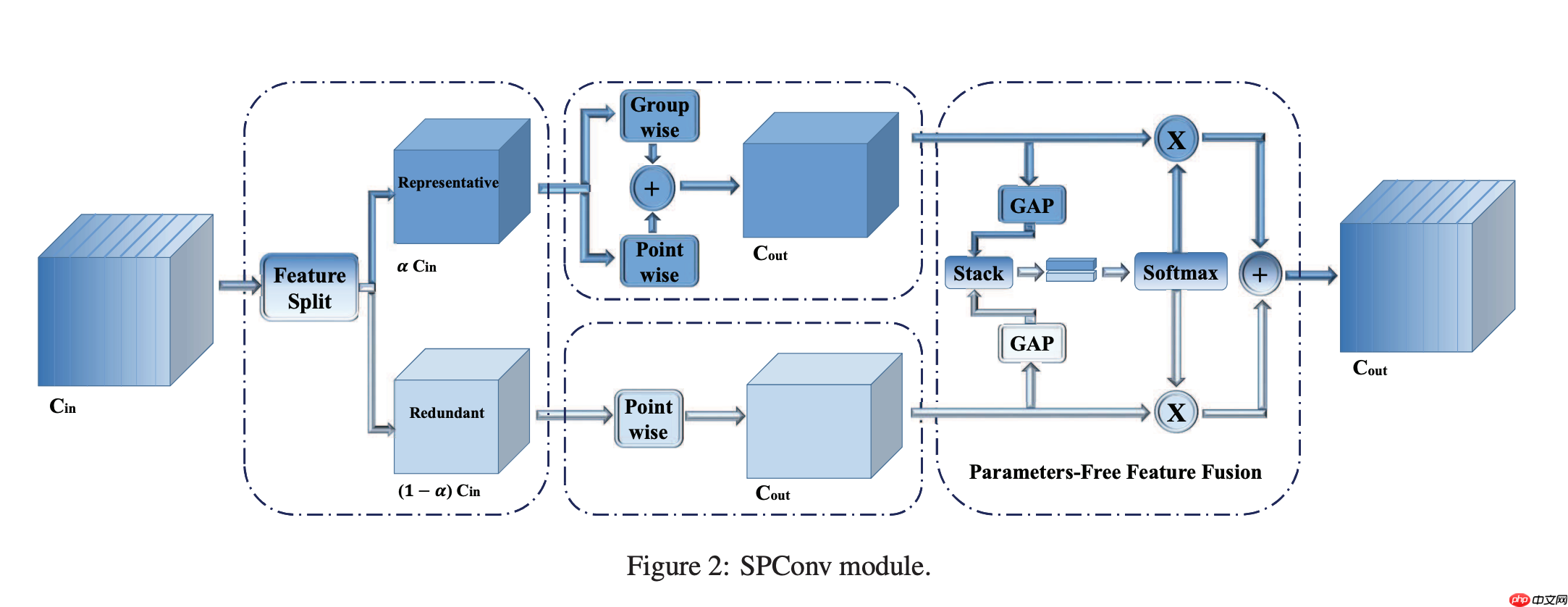
在现有的滤波器中,比如常规卷积、GhostConv、OctConv、HetConv均在所有输入通道上执行k*k卷积。然而,如上图所示,同一层的特征中存在相似模式,也就是说存在特征冗余问题。但同时,并未存在完全相同的两个通道特征,进而导致无法直接剔除冗余通道特征。
受此现象启发,作者提出将所有输入特征按比例拆分为两部分:
(1) Representative部分执行k*k卷积提取重要信息;
(2) Uncertain部分执行1*1卷积补充隐含细节信息。
因此该过程可以描述为(见SPConv的左侧部分),公式如下图所示:
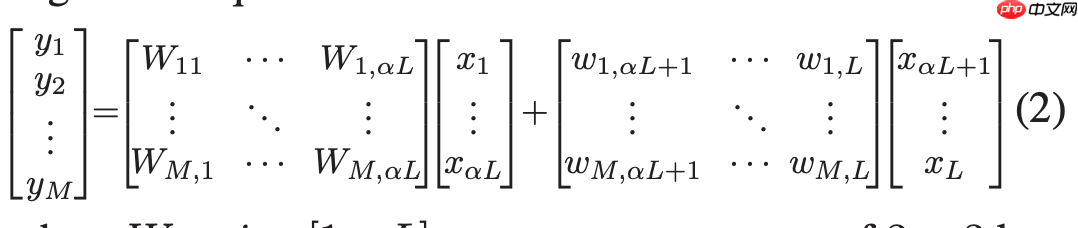
- 代码复现
import paddleimport paddle.nn as nndef conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2D(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, dilation=dilation)class SPConv_3x3(nn.Layer):
def __init__(self, inplanes=32, outplanes=32, stride=1, ratio=0.5):
super(SPConv_3x3, self).__init__()
self.inplanes_3x3 = int(inplanes*ratio)
self.inplanes_1x1 = inplanes - self.inplanes_3x3
self.outplanes_3x3 = int(outplanes*ratio)
self.outplanes_1x1 = outplanes - self.outplanes_3x3
self.outplanes = outplanes
self.stride = stride
self.gwc = nn.Conv2D(self.inplanes_3x3, self.outplanes, kernel_size=3, stride=self.stride,
padding=1, groups=2)
self.pwc = nn.Conv2D(self.inplanes_3x3, self.outplanes, kernel_size=1)
self.conv1x1 = nn.Conv2D(self.inplanes_1x1, self.outplanes,kernel_size=1)
self.avgpool_s2_1 = nn.AvgPool2D(kernel_size=2,stride=2)
self.avgpool_s2_3 = nn.AvgPool2D(kernel_size=2, stride=2)
self.avgpool_add_1 = nn.AdaptiveAvgPool2D(1)
self.avgpool_add_3 = nn.AdaptiveAvgPool2D(1)
self.bn1 = nn.BatchNorm2D(self.outplanes)
self.bn2 = nn.BatchNorm2D(self.outplanes)
self.ratio = ratio
self.groups = int(1/self.ratio) def forward(self, x):
# print(x.shape)
b, c, _, _ = x.shape
x_3x3 = x[:,:int(c*self.ratio),:,:]
x_1x1 = x[:,int(c*self.ratio):,:,:]
out_3x3_gwc = self.gwc(x_3x3) if self.stride ==2:
x_3x3 = self.avgpool_s2_3(x_3x3)
out_3x3_pwc = self.pwc(x_3x3)
out_3x3 = out_3x3_gwc + out_3x3_pwc
out_3x3 = self.bn1(out_3x3)
out_3x3_ratio = self.avgpool_add_3(out_3x3).squeeze(axis=3).squeeze(axis=2) # use avgpool first to reduce information lost
if self.stride == 2:
x_1x1 = self.avgpool_s2_1(x_1x1)
out_1x1 = self.conv1x1(x_1x1)
out_1x1 = self.bn2(out_1x1)
out_1x1_ratio = self.avgpool_add_1(out_1x1).squeeze(axis=3).squeeze(axis=2)
out_31_ratio = paddle.stack((out_3x3_ratio, out_1x1_ratio), 2)
out_31_ratio = nn.Softmax(axis=2)(out_31_ratio)
out = out_1x1 * (out_31_ratio[:,:,1].reshape([b, self.outplanes, 1, 1]).expand_as(out_1x1))\
+ out_3x3 * (out_31_ratio[:,:,0].reshape([b, self.outplanes, 1, 1]).expand_as(out_3x3)) return out
paddle.summary(SPConv_3x3(), (1,32,224,224))1.2 即插即用型卷积:PyConv复现
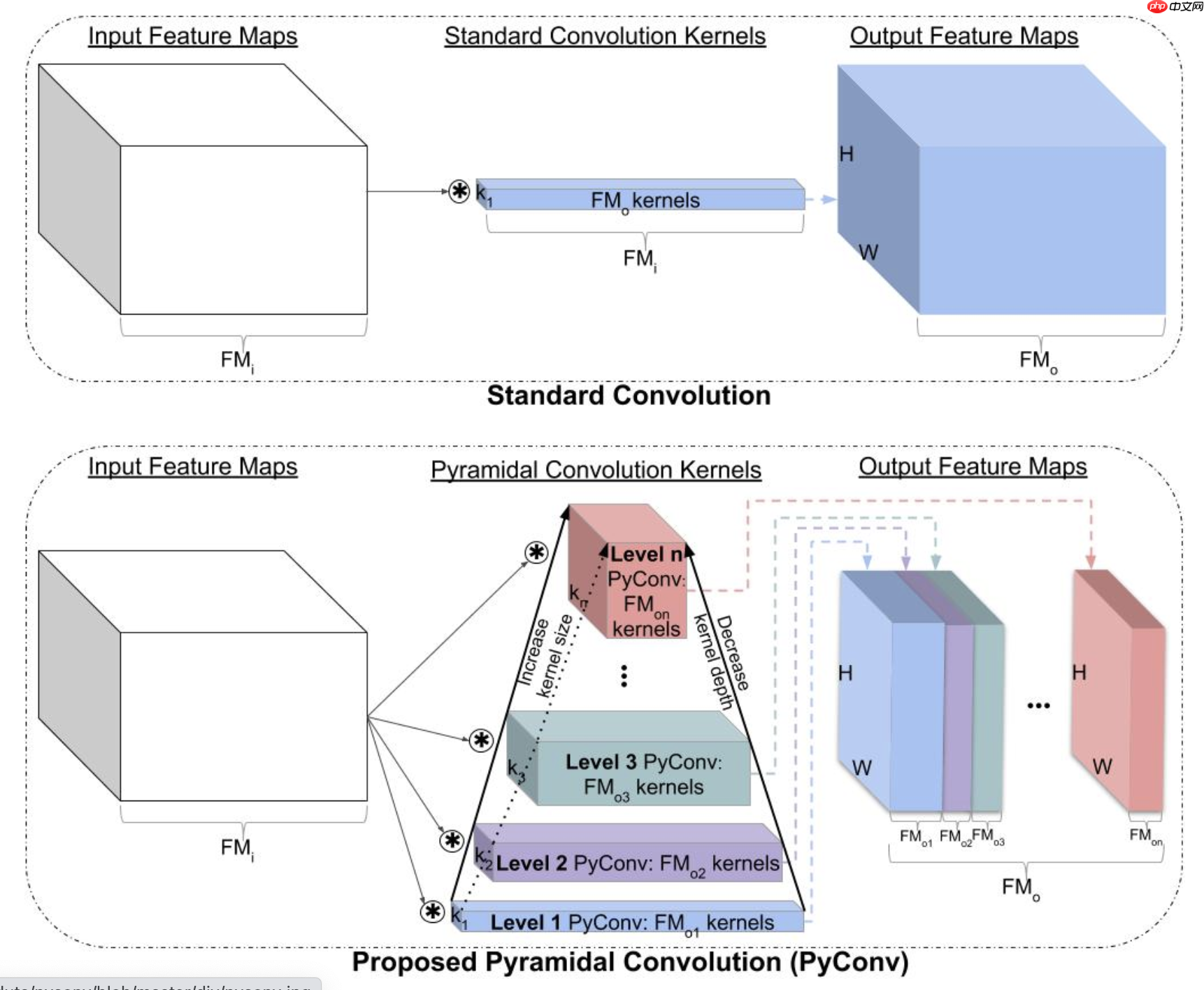
如上图所示,标准的卷积操作中,每个卷积核的通道和input feature的通道一致。 PyConv中,随着卷积核size增大,通道大小减少,此时需要使用Grouped Convolution。Group分组的对象是input feature的通道,每n个为一组。
类似Inception分支和ASPP模块,提出使用不同卷积核的多分支网络。与类似模块大部分使用不同空洞卷积核的是PyConv提出使用分组卷积的思想。PyConv中多分支使用不同大小的卷积核,论文中包括33,55,77,99的卷积核。一般的,较小的卷积核感受野较小,可以得到小目标和局部细节信息。较大的卷积核感受野较大,可以得到大目标和全局语义信息。分组卷积是将输入特征图切分成不同组,使用卷积核独立处理。论文中提出两个版本,PyConv和PyHGConv。PyConv中使用相对较小的分组数,包括16,8,4,2。PyHGConv使用较大的分组数,包括32和64。在backbone结合时考虑到特征图的空间尺寸减小,分支数逐渐减少。最初阶段特征图通过四个分支,最后阶段特征图仅使用一个分支。语义分割任务中在一般网络中添加局部PyConv模块和全局PyConv模块。这两个模块都包括使用1*1卷积将通道数增加到512,后使用四分支的PyConv模块,卷积核包括9,7,5,3,分组数分别为16,8,4,2。不同的是全局PyConv模块需要使用Adaptive平均池化层减少特征图大小同时提取全局特征。PyConv分支后使用上采样恢复原始尺寸。之后将局部PyConv提取的特征和全局PyConv提取的特征合并。
- 代码复现
import paddle.nn as nnimport paddle
class PyConv2d(nn.Layer): """PyConv2d with padding (general case). Applies a 2D PyConv over an input signal composed of several input planes.
Args:
in_channels (int): Number of channels in the input image
out_channels (list): Number of channels for each pyramid level produced by the convolution
pyconv_kernels (list): Spatial size of the kernel for each pyramid level
pyconv_groups (list): Number of blocked connections from input channels to output channels for each pyramid level
stride (int or tuple, optional): Stride of the convolution. Default: 1
dilation (int or tuple, optional): Spacing between kernel elements. Default: 1
bias (bool, optional): If ``True``, adds a learnable bias to the output. Default: ``False``
Example::
>>> # PyConv with two pyramid levels, kernels: 3x3, 5x5
>>> m = PyConv2d(in_channels=64, out_channels=[32, 32], pyconv_kernels=[3, 5], pyconv_groups=[1, 4])
>>> input = paddle.randn(4, 64, 56, 56)
>>> output = m(input)
>>> # PyConv with three pyramid levels, kernels: 3x3, 5x5, 7x7
>>> m = PyConv2d(in_channels=64, out_channels=[16, 16, 32], pyconv_kernels=[3, 5, 7], pyconv_groups=[1, 4, 8])
>>> input = paddle.randn(4, 64, 56, 56)
>>> output = m(input) """
def __init__(self, in_channels, out_channels, pyconv_kernels, pyconv_groups, stride=1, dilation=1):
super(PyConv2d, self).__init__()
assert len(out_channels) == len(pyconv_kernels) == len(pyconv_groups)
self.pyconv_levels = [None] * len(pyconv_kernels) for i in range(len(pyconv_kernels)):
self.pyconv_levels[i] = nn.Conv2D(in_channels, out_channels[i], kernel_size=pyconv_kernels[i],
stride=stride, padding=pyconv_kernels[i] // 2, groups=pyconv_groups[i],
dilation=dilation, )
self.pyconv_levels = nn.LayerList(self.pyconv_levels)
def forward(self, x):
out = [] for level in self.pyconv_levels:
out.append(level(x)) return paddle.concat(out, 1)1.3 给你的神经网络降低一个八度:八度卷积飞桨版本复现
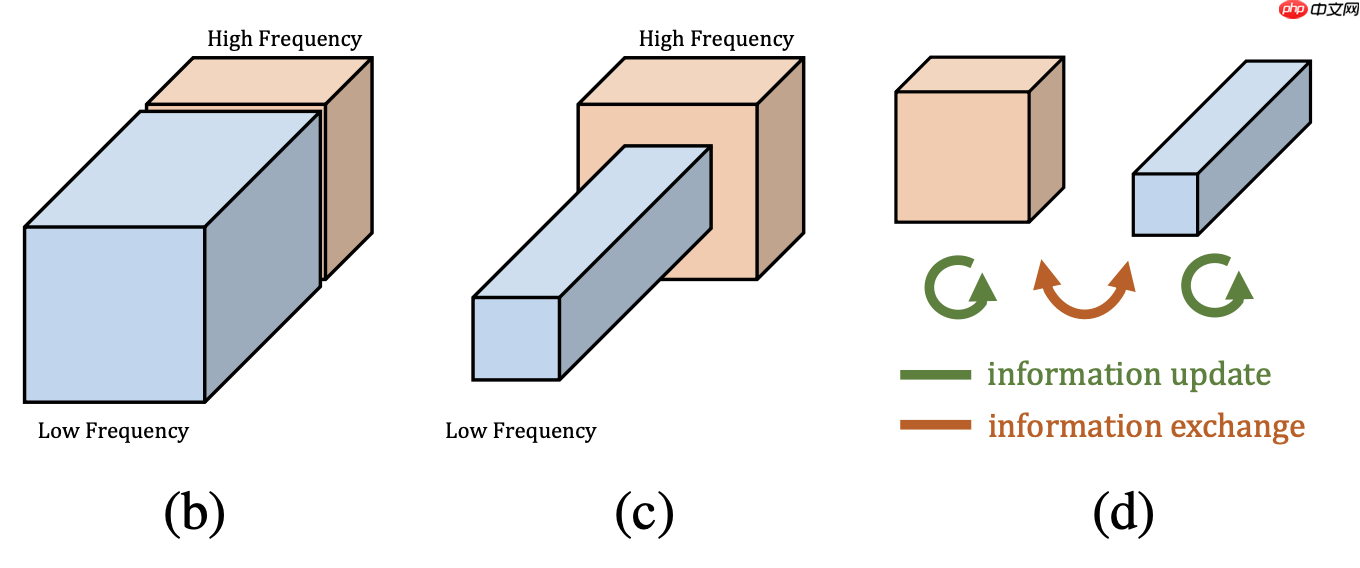
在论文中,作者提出较高的频率通常用精细的细节编码,较低的频率通常用全局结构编码。所以作者认为那么既然图像分为高低频,那么卷积产生的特征图自然也存在高低频之分。在图像处理中,模型通过高频特征图去学习图像包含的信息,因为它包含了轮廓、边缘等的信息,有助于进行显著性检测。相反,低频特征图包含的信息较少。如果我们用相同的处理方法来处理高频特征图和低频特征图,显然,前者的效益是远大于后者的。这就是特征图的冗余信息:包含信息较少的低频部分。所以在论文中作者提出了一种分而治之的方法,称之为Octave Feature Representation,对高频特征图与低频特征图分离开来进行处理。如下图所示,作者将低频特征图的分辨率降为1/2,这不仅有助于减少冗余数据,还有利于得到全局信息。
- 代码复现
import paddleimport paddle.nn as nnimport mathclass OctaveConv(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size, alpha_in=0.5, alpha_out=0.5, stride=1, padding=0, dilation=1,
groups=1, bias=False):
super(OctaveConv, self).__init__()
self.downsample = nn.AvgPool2D(kernel_size=(2, 2), stride=2)
self.upsample = nn.Upsample(scale_factor=2, mode='nearest') assert stride == 1 or stride == 2, "Stride should be 1 or 2."
self.stride = stride
self.is_dw = groups == in_channels assert 0 <= alpha_in <= 1 and 0 <= alpha_out <= 1, "Alphas should be in the interval from 0 to 1."
self.alpha_in, self.alpha_out = alpha_in, alpha_out
self.conv_l2l = None if alpha_in == 0 or alpha_out == 0 else \
nn.Conv2D(int(alpha_in * in_channels), int(alpha_out * out_channels),
kernel_size, 1, padding, dilation, math.ceil(alpha_in * groups))
self.conv_l2h = None if alpha_in == 0 or alpha_out == 1 or self.is_dw else \
nn.Conv2D(int(alpha_in * in_channels), out_channels - int(alpha_out * out_channels),
kernel_size, 1, padding, dilation, groups)
self.conv_h2l = None if alpha_in == 1 or alpha_out == 0 or self.is_dw else \
nn.Conv2D(in_channels - int(alpha_in * in_channels), int(alpha_out * out_channels),
kernel_size, 1, padding, dilation, groups)
self.conv_h2h = None if alpha_in == 1 or alpha_out == 1 else \
nn.Conv2D(in_channels - int(alpha_in * in_channels), out_channels - int(alpha_out * out_channels),
kernel_size, 1, padding, dilation, math.ceil(groups - alpha_in * groups)) def forward(self, x):
x_h, x_l = x if type(x) is tuple else (x, None)
x_h = self.downsample(x_h) if self.stride == 2 else x_h
x_h2h = self.conv_h2h(x_h)
x_h2l = self.conv_h2l(self.downsample(x_h)) if self.alpha_out > 0 and not self.is_dw else None
if x_l is not None:
x_l2l = self.downsample(x_l) if self.stride == 2 else x_l
x_l2l = self.conv_l2l(x_l2l) if self.alpha_out > 0 else None
if self.is_dw: return x_h2h, x_l2l else:
x_l2h = self.conv_l2h(x_l)
x_l2h = self.upsample(x_l2h) if self.stride == 1 else x_l2h
x_h = x_l2h + x_h2h
x_l = x_h2l + x_l2l if x_h2l is not None and x_l2l is not None else None
return x_h, x_l else: return x_h2h, x_h2l1.4 【动手学Paddle2.0系列】CoordConv实战
深度学习里的卷积运算是具有平移等变性的,这样可以在图像的不同位置共享统一的卷积核参数,但是这样卷积学习过程中是不能感知当前特征在图像中的坐标的。CoordConv就是通过在卷积的输入特征图中新增对应的通道来表征特征图像素点的坐标,让卷积学习过程中能够一定程度感知坐标来提升检测精度。
即它无法将空间表示转换成笛卡尔空间中的坐标和one-hot像素空间中的坐标。 卷积是等变的,也就是说当每个过滤器应用到输入上时,它不知道每个过滤器在哪。我们可以帮助卷积,让它知道过滤器的位置。这一过程需要在输入上添加两个通道实现,一个在i坐标,另一个在j坐标。我们将这个图层成为CoordConv,如下图所示:
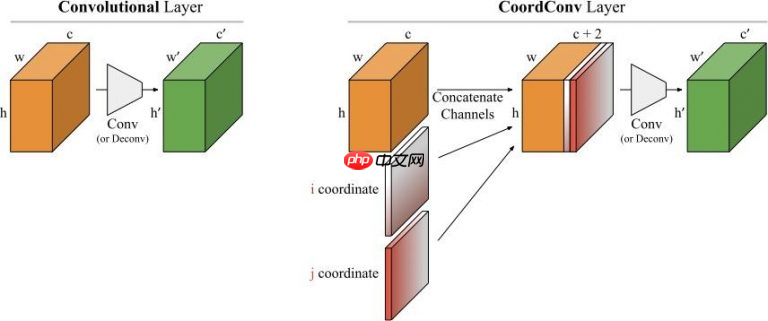
- 代码复现
class CoordConv(nn.Layer): def __init__(self, in_channels, out_channels, kernel_size, stride, padding): super(CoordConv, self).__init__() self.conv = Conv2D( in_channels + 2, out_channels , kernel_size , stride , padding) def forward(self, x): b = x.shape[0] h = x.shape[2] w = x.shape[3] gx = paddle.arange(w, dtype='float32') / (w - 1.) * 2.0 - 1. gx = gx.reshape([1, 1, 1, w]).expand([b, 1, h, w]) gx.stop_gradient = True gy = paddle.arange(h, dtype='float32') / (h - 1.) * 2.0 - 1. gy = gy.reshape([1, 1, h, 1]).expand([b, 1, h, w]) gy.stop_gradient = True y = paddle.concat([x, gx, gy], axis=1) y = self.conv(y) return y
1.5 【动手学Paddle2.0系列】可变形卷积DCN实战
这里我们首先看一下我们正常使用的规整卷积和可变形卷积之间的对比图。如下图所示:
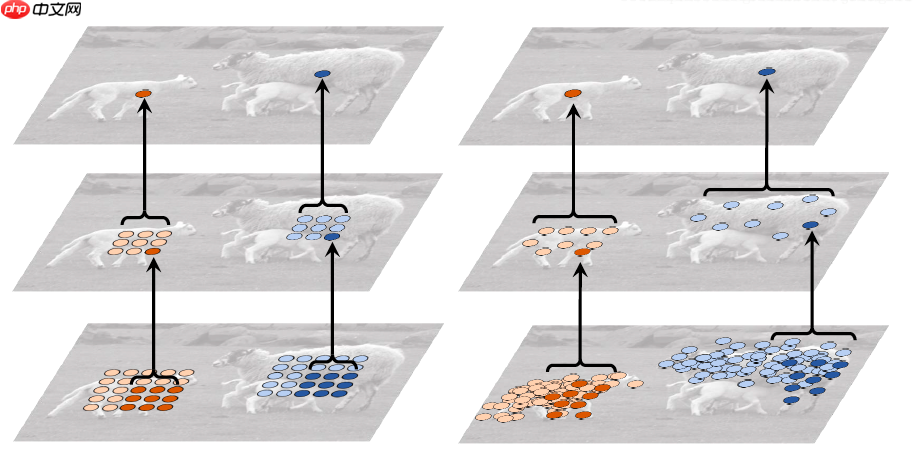
我们可以看到在理想情况下,可变形卷积能够比规整卷积学习到更加有效的图像特征。
现在我们反推一下为什么这种卷积结构会比经典的卷积结构更有效?在论文中,作者给出的回答是:经典卷积神经网络的卷积结构固定,对目标建模不充分。图像不同位置的结构应当是不同的,但是却用相同结构的卷积进行计算;不管当前位置的图像是什么结构,都使用固定比例的池化层降低特征图分辨率。这种做法是不可取的,尤其是对非刚性目标。
接下来,我们思考一下该如何实现这种卷积的形变,我们明确一点,在这里我们不可能真的让卷积核进行形变,那我们该如何实现呢?答案如下所示,通过给卷积的位置加一个偏移值(offset)来实现卷积的“变形”,加上该偏移量的学习之后,可变形卷积核的大小和位置能够根据图像内容进行动态调整,其直观效果就是不同位置的卷积核采样点位置会根据图像内容发生自适应变化,从而适应不同目标物体的几何形变。
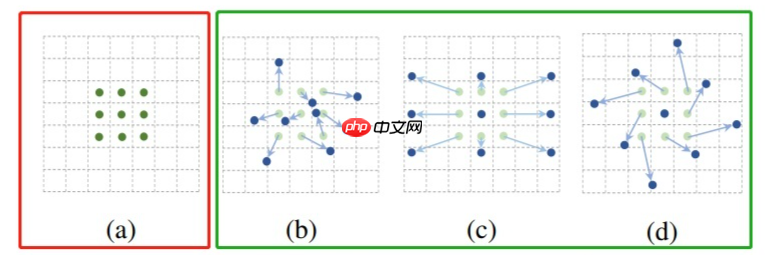
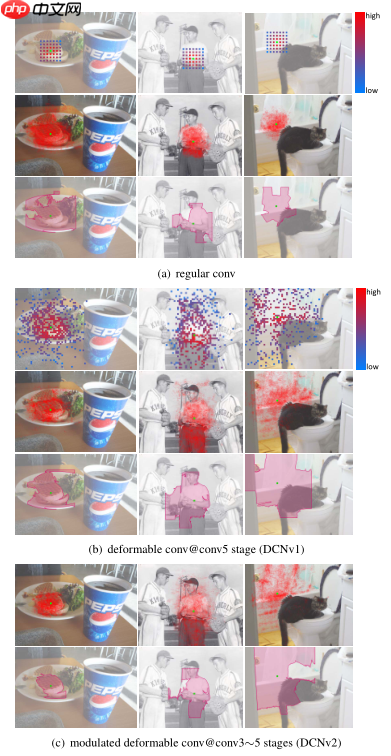
以上是DCNv1的主要思想,在之后DCNv2主要做了两点改进,一是在网络结构中增加了可变形卷积层的使用(Stacking More Deformable Conv Layers),二是在偏移值上又增加了一个权值(Modulated Deformable Modules)。对于DCNv1,作者发现在实际的应用中,其感受野对应位置超出了目标范围,导致特征不受图像内容影响。在DCNv2中,其主要改进点为引入了幅度调制机制,让网络学习到每一个采样点偏移量的同时也学习到这一采样点的幅度(即该特征点对应的权重。)使得网络在具备学习空间形变能力的同时具备区分采样点重要性的能力。(此改进是否为注意力机制?)
2、池化操作部分
2.1 重新思考神经网络的平移不变性:反锯齿下采样论文复现
在论文Making Convolutional Networks Shift-Invariant Again,baseline展示了CNN网络的预测结果随着图像变化而大幅变化,即当目标平移几个像素之后,目标则不能被正确的预测。作者考虑了CNN网络的各个结构,认为卷积层本身是具有平移不变性的,而池化层破坏了平移不变性。作者认为可以借鉴信号处理中反锯齿算法的设计,即在信号下采样之前进行低通滤波(也就是图像模糊),缓解池化操作带来的对平移不变性的破坏。其具体做法如下图所示: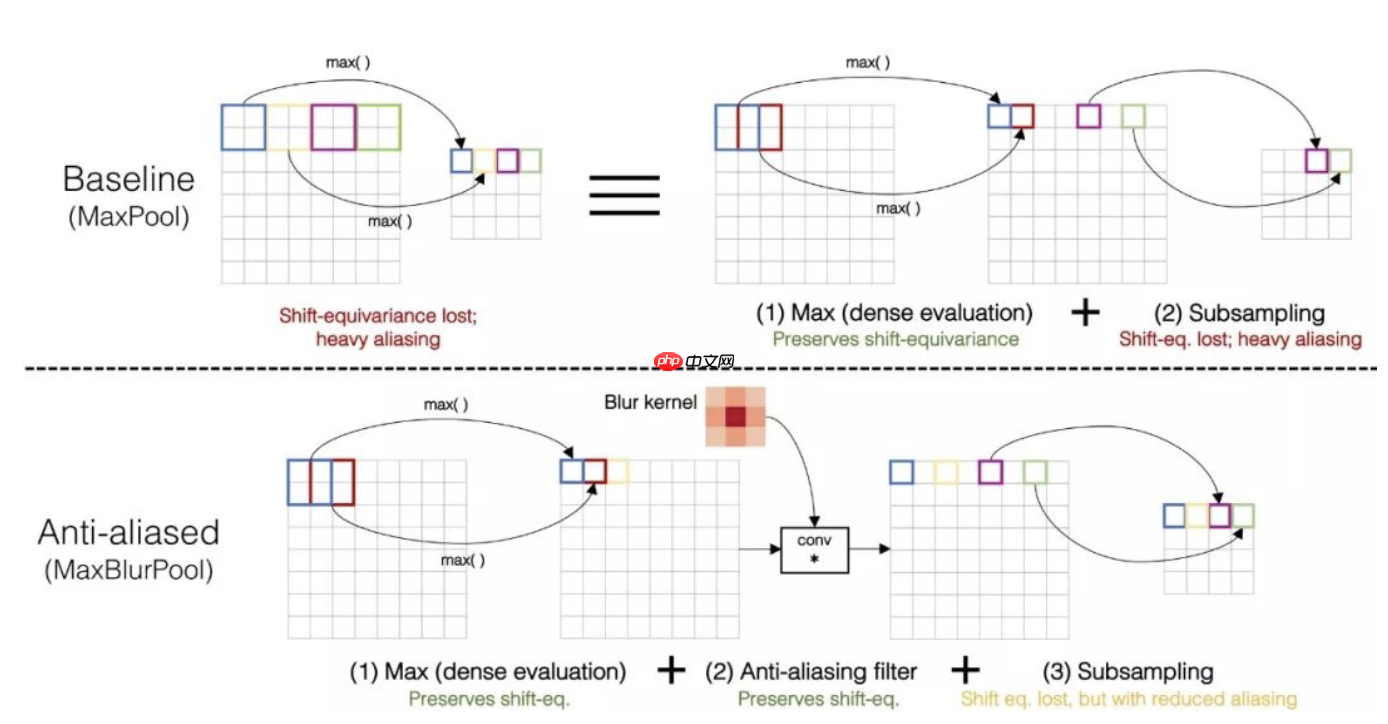
在论文中,作者展示了原始的MaxPool操作,作者将其看为两步,先Max,再下采样。 作者的做法是在Max之后加一步图像模糊,作者对StridedConv与AveragePool等涉及到下采样的网络操作都进行了改进,成为ConvBlurPool、BlurPool,即都是在下采样之前进行模糊操作。实验中也研究使用了不同类型和参数的模糊核。
- 代码复现
import paddleimport numpy as npimport paddle.nn as nnimport paddle.nn.functional as Fdef get_pad_layer(pad_type):
if(pad_type in ['refl','reflect']):
PadLayer = nn.Pad2D elif(pad_type in ['repl','replicate']):
PadLayer = nn.Pad2D elif(pad_type=='zero'):
PadLayer = nn.ZeroPad2D else: print('Pad type [%s] not recognized'%pad_type) return PadLayerclass BlurPool(nn.Layer):
def __init__(self, channels, pad_type='reflect', filt_size=4, stride=2, pad_off=0):
super(BlurPool, self).__init__()
self.filt_size = filt_size
self.pad_off = pad_off
self.pad_sizes = [int(1.*(filt_size-1)/2), int(np.ceil(1.*(filt_size-1)/2)), int(1.*(filt_size-1)/2), int(np.ceil(1.*(filt_size-1)/2))]
self.pad_sizes = [pad_size+pad_off for pad_size in self.pad_sizes]
self.stride = stride
self.off = int((self.stride-1)/2.)
self.channels = channels if(self.filt_size==1):
a = np.array([1.,]) elif(self.filt_size==2):
a = np.array([1., 1.]) elif(self.filt_size==3):
a = np.array([1., 2., 1.]) elif(self.filt_size==4):
a = np.array([1., 3., 3., 1.]) elif(self.filt_size==5):
a = np.array([1., 4., 6., 4., 1.]) elif(self.filt_size==6):
a = np.array([1., 5., 10., 10., 5., 1.]) elif(self.filt_size==7):
a = np.array([1., 6., 15., 20., 15., 6., 1.])
filt = paddle.Tensor(a[:,None]*a[None,:])
filt = filt/paddle.sum(filt) # self.register_buffer('filt', filt[None,None,:,:].repeat((self.channels,1,1,1)))
self.pad = get_pad_layer(pad_type)(self.pad_sizes) def forward(self, inp):
if(self.filt_size==1): if(self.pad_off==0): return inp[:,:,::self.stride,::self.stride]
else: return self.pad(inp)[:,:,::self.stride,::self.stride] else: return F.conv2D(self.pad(inp), self.filt, stride=self.stride, groups=inp.shape[1])2.2 【AI达人特训营】ResNet50-NAM:一种新的注意力计算方式复现
NAM是一种轻量级的高效的注意力机制,我们采用了CBAM的模块集成方式,重新设计了通道注意力和空间注意力子模块,这样,NAM可以嵌入到每个网络block的最后。对于残差网络,可以嵌入到残差结构的最后。对于通道注意力子模块,我们使用了Batch Normalization中的缩放因子,如式子(1),缩放因子反映出各个通道的变化的大小,也表示了该通道的重要性。为什么这么说呢,可以这样理解,缩放因子即BN中的方差,方差越大表示该通道变化的越厉害,那么该通道中包含的信息会越丰富,重要性也越大,而那些变化不大的通道,信息单一,重要性小。 
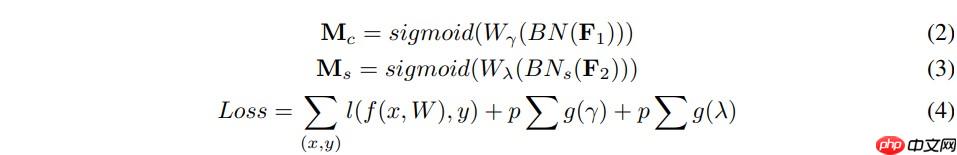
其中μB和σB为均值,B为标准差,γ和β是可训练的仿射变换参数(尺度和位移)参考Batch Normalization.通道注意力子模块如图(1)和式(2)所示: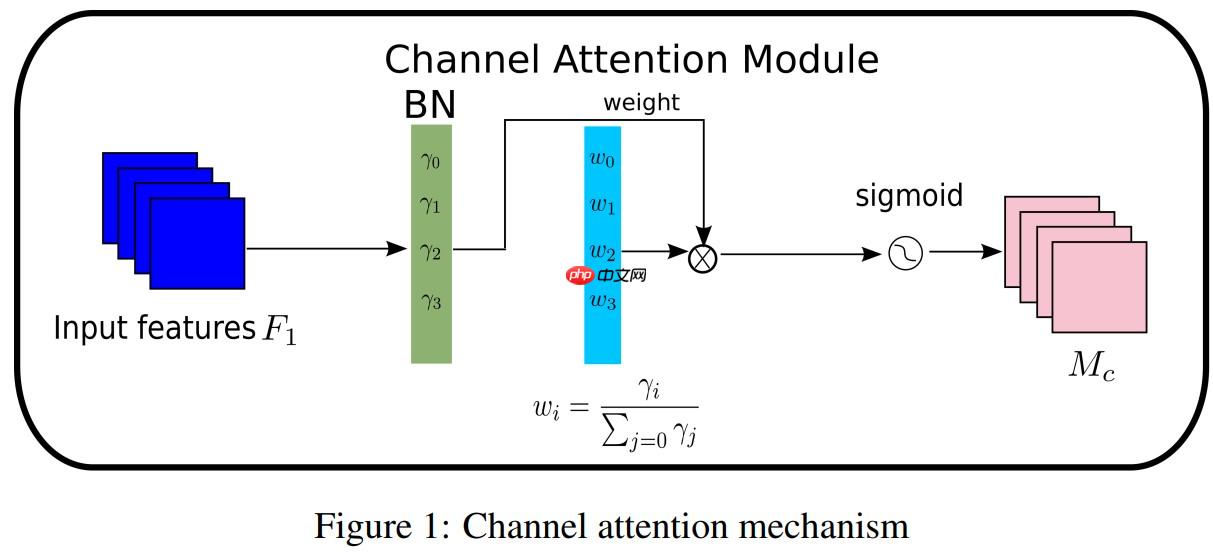
其中Mc表示最后得到的输出特征,γ是每个通道的缩放因子,因此,每个通道的权值可以通过 Wγ=γi/∑j=0γj 得到。我们也使用一个缩放因子 BN 来计算注意力权重,称为像素归一化。像素注意力如图(2)和式(3)所示: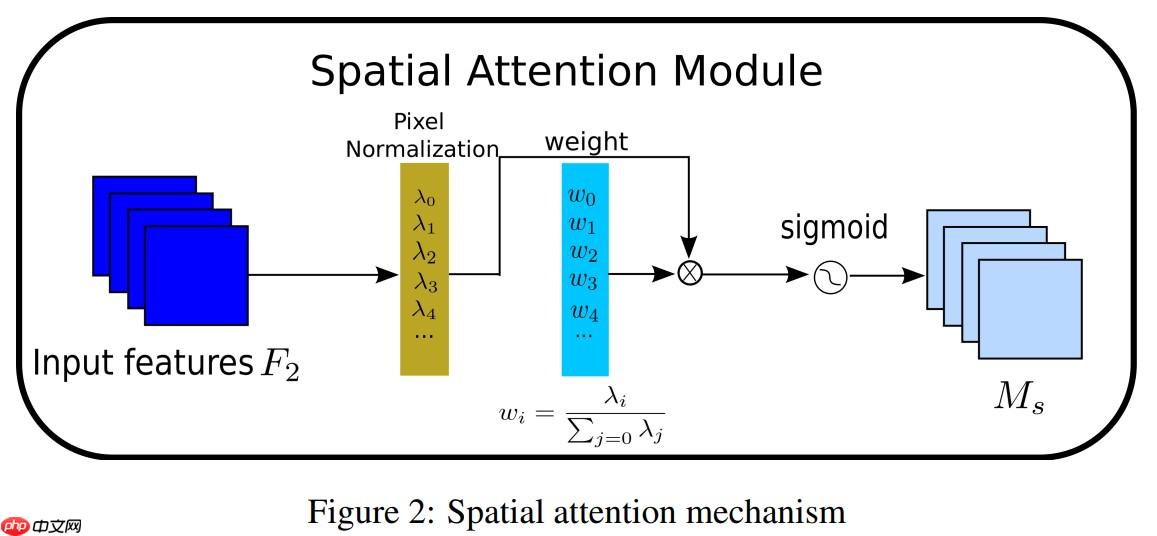
为了抑制不重要的特征,作者在损失函数中加入了一个正则化项,如式(4)所示。
- 代码复现
import paddle.nn as nnimport paddlefrom paddle.nn import functional as Fclass Channel_Att(nn.Layer):
def __init__(self, channels=3, t=16):
super(Channel_Att, self).__init__()
self.channels = channels
self.bn2 = nn.BatchNorm2D(self.channels) def forward(self, x):
residual = x
x = self.bn2(x)
weight_bn = self.bn2.weight.abs() / paddle.sum(self.bn2.weight.abs())
x = x.transpose([0, 2, 3, 1])
x = paddle.multiply(weight_bn, x)
x = x.transpose([0, 3, 1, 2])
x = F.sigmoid(x) * residual #
return xclass Att(nn.Layer):
def __init__(self, channels=3, out_channels=None, no_spatial=True):
super(Att, self).__init__()
self.Channel_Att = Channel_Att(channels)
def forward(self, x):
x_out1=self.Channel_Att(x)
return x_out13、激活函数部分
3.1 重新思考神经网络的激活函数:Dynamic ReLU复现
ReLU是深度学习中很重要的里程碑,简单但强大,能够极大地提升神经网络的性能。目前也有很多ReLU的改进版,比如Leaky ReLU和 PReLU,而这些改进版和原版的最终参数都是固定的。所以论文自然而然地想到,如果能够根据输入特征来调整ReLU的参数可能会更好。
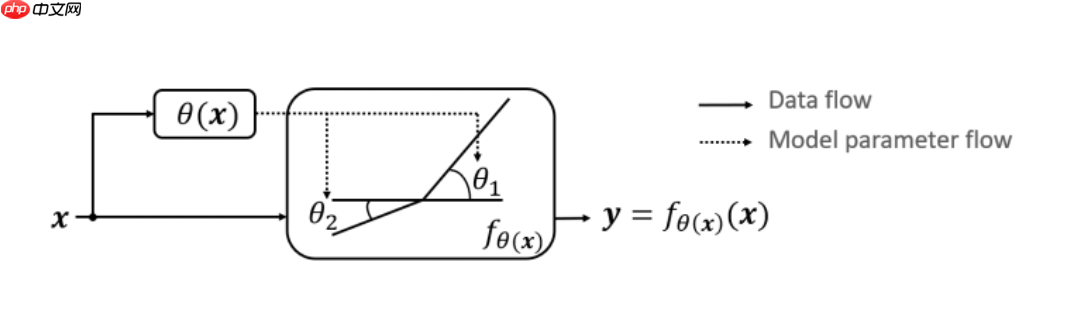
如上图所示,论文中提出的Dynamic ReLU是一种分段函数,能够在带来少量额外计算的情况下,显著地提高网络的表达能力。
论文提供了三种形态的DY-ReLU,在空间位置和维度上有不同的共享机制,如下图所示:

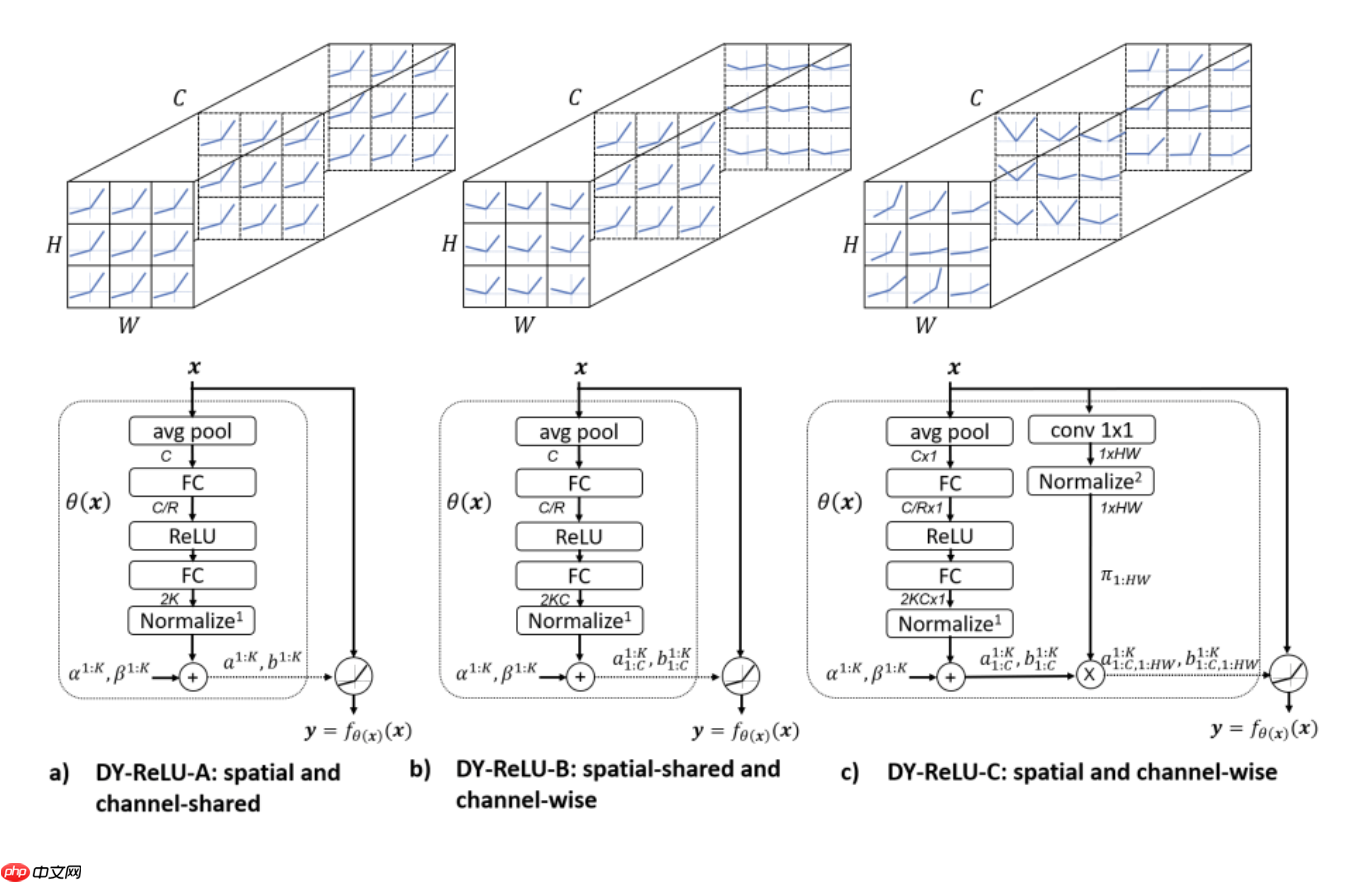
- 代码复现
import paddleimport paddle.nn as nnclass DyReLU(nn.Layer):
def __init__(self, channels, reduction=4, k=2, conv_type='2d'):
super(DyReLU, self).__init__()
self.channels = channels
self.k = k
self.conv_type = conv_type assert self.conv_type in ['1d', '2d']
self.fc1 = nn.Linear(channels, channels // reduction)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(channels // reduction, 2*k)
self.sigmoid = nn.Sigmoid()
self.register_buffer('lambdas', paddle.to_tensor([1.]*k + [0.5]*k))
self.register_buffer('init_v', paddle.to_tensor([1.] + [0.]*(2*k - 1))) def get_relu_coefs(self, x):
theta = paddle.mean(x, axis=-1) if self.conv_type == '2d':
theta = paddle.mean(theta, axis=-1)
theta = self.fc1(theta)
theta = self.relu(theta)
theta = self.fc2(theta)
theta = 2 * self.sigmoid(theta) - 1
return theta def forward(self, x):
raise NotImplementedErrorclass DyReLUA(DyReLU):
def __init__(self, channels, reduction=4, k=2, conv_type='2d'):
super(DyReLUA, self).__init__(channels, reduction, k, conv_type)
self.fc2 = nn.Linear(channels // reduction, 2*k) def forward(self, x):
assert x.shape[1] == self.channels
theta = self.get_relu_coefs(x)
relu_coefs = theta.view(-1, 2*self.k) * self.lambdas + self.init_v # BxCxL -> LxCxBx1
x_perm = x.transpose(0, -1).unsqueeze(-1)
output = x_perm * relu_coefs[:, :self.k] + relu_coefs[:, self.k:] # LxCxBx2 -> BxCxL
result = paddle.max(output, dim=-1)[0].transpose(0, -1) return resultclass DyReLUB(DyReLU):
def __init__(self, channels, reduction=4, k=2, conv_type='2d'):
super(DyReLUB, self).__init__(channels, reduction, k, conv_type)
self.fc2 = nn.Linear(channels // reduction, 2*k*channels) def forward(self, x):
assert x.shape[1] == self.channels
theta = self.get_relu_coefs(x)
relu_coefs = theta.reshape([-1, self.channels, 2*self.k]) * self.lambdas + self.init_v if self.conv_type == '1d': # BxCxL -> LxBxCx1
x_perm = x.transpose([2, 0, 1]).unsqueeze(-1)
output = x_perm * relu_coefs[:, :, :self.k] + relu_coefs[:, :, self.k:] # LxBxCx2 -> BxCxL
result = paddle.max(output, axis=-1)[0].transpose([1, 2, 0]) elif self.conv_type == '2d': # BxCxHxW -> HxWxBxCx1
x_perm = x.transpose([2, 3, 0, 1]).unsqueeze(-1) # print(x.shape)
output = x_perm * relu_coefs[:, :, :self.k] + relu_coefs[:, :, self.k:] # print(output.shape)
# HxWxBxCx2 -> BxCxHxW
# temp = paddle.max(output, axis=-1)
# print(temp.shape)
result = paddle.max(output, axis=-1).transpose([2, 3, 0, 1]) return result3.2 ACON激活函数复现
我们目前常用的激活函数本质上都是MAX函数,以ReLU函数为例,其形式可以表示为:
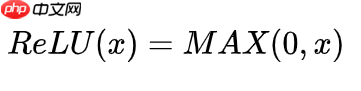
而MAX函数的平滑,可微分变体我们称为Smooth Maximum,其公式如下:
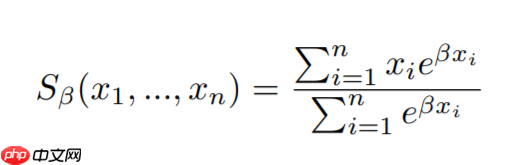
这里我们只考虑Smooth Maximum只有两个输入量的情况,即n=2,于是有以下公式:
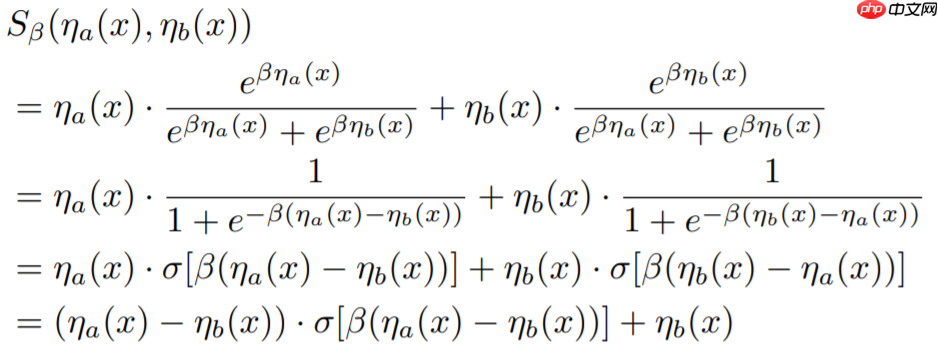
考虑平滑形式下的ReLU ,代入公式我们得到而这个结果
,代入公式我们得到而这个结果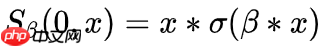 就是Swish激活函数!所以我们可以得到,Swish激活函数是ReLU函数的一种平滑近似。我们称其为ACON-A:
就是Swish激活函数!所以我们可以得到,Swish激活函数是ReLU函数的一种平滑近似。我们称其为ACON-A:
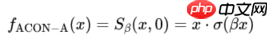
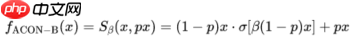
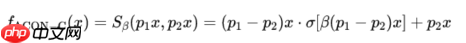
ACON-C的一阶导数计算公式如下所示:
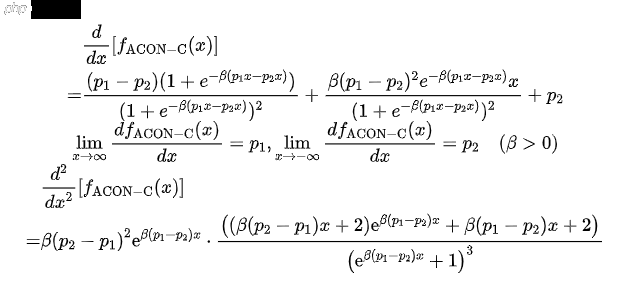
解上述方程可得:

可学习的边界对于简化优化是必不可少的,这些可学习的上界和下届是改善结果的关键。
- 代码复现
import paddlefrom paddle import nnimport paddle.nn.functional as Ffrom paddle import ParamAttrfrom paddle.regularizer import L2Decayfrom paddle.nn import AvgPool2D, Conv2Dimport numpy as npclass AconC(nn.Layer):
""" ACON activation (activate or not).
# AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter
# according to "Activate or Not: Learning Customized Activation" .
"""
def __init__(self, width):
super().__init__()
self.p1 = paddle.create_parameter([1, width, 1, 1], dtype='float32', default_initializer=nn.initializer.Normal())
self.p2 = paddle.create_parameter([1, width, 1, 1], dtype='float32', default_initializer=nn.initializer.Normal())
self.beta = paddle.create_parameter([1, width, 1, 1], dtype='float32', default_initializer=paddle.fluid.initializer.NumpyArrayInitializer(np.ones([1, width, 1, 1]))) def forward(self, x):
return (self.p1 * x - self.p2 * x) * F.sigmoid(self.beta * (self.p1 * x - self.p2 * x)) + self.p2 * x 4、网络结构部分
4.1 基于SPPNET的图像分类网络
对于Spatial Pyramid Pooling(SPP)特征金字塔池化在本项目中做了一个复现,并基于此模块搭建了一个图像分类网络,并在Cifar10数据库中进行了实验。
由于卷积神经网络的全连接层需要固定输入的尺寸,而Selective search所得到的候选区域存在尺寸上的差异,无法直接输入到卷积神经网络中实现区域的特征提取,因此RCNN先将候选区缩放至指定大小随后再输入到模型中进行特征提取直接对区域进行裁剪会导致区域缺失,而将区域缩放则可能导致目标过度形变而导致后续分类错误(例如筷子是细长形的,如果将其直接形变成正方形则会使其严重失真而错误分类)。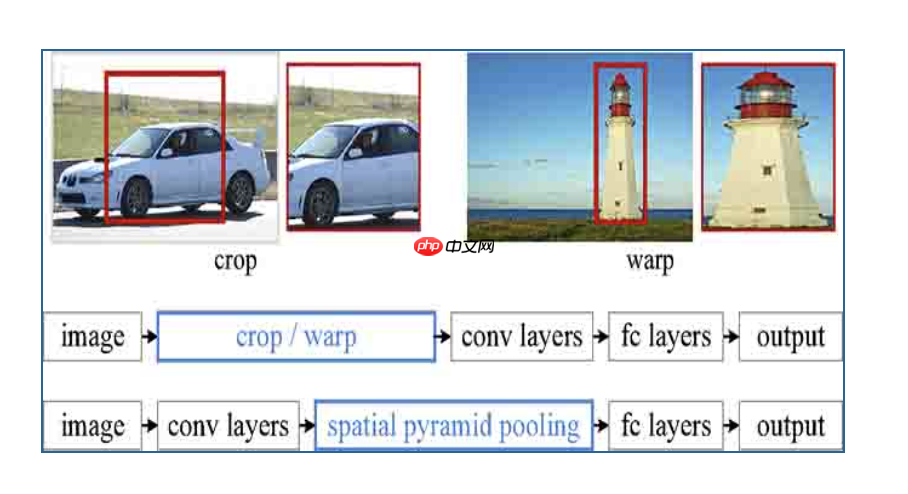
如上图所示,直接对区域进行裁剪会导致区域缺失,而将区域缩放则可能导致目标过度形变而导致后续分类错误(例如筷子是细长形的,如果将其直接形变成正方形则会使其严重失真而错误分类)。其主要结构如下图所示: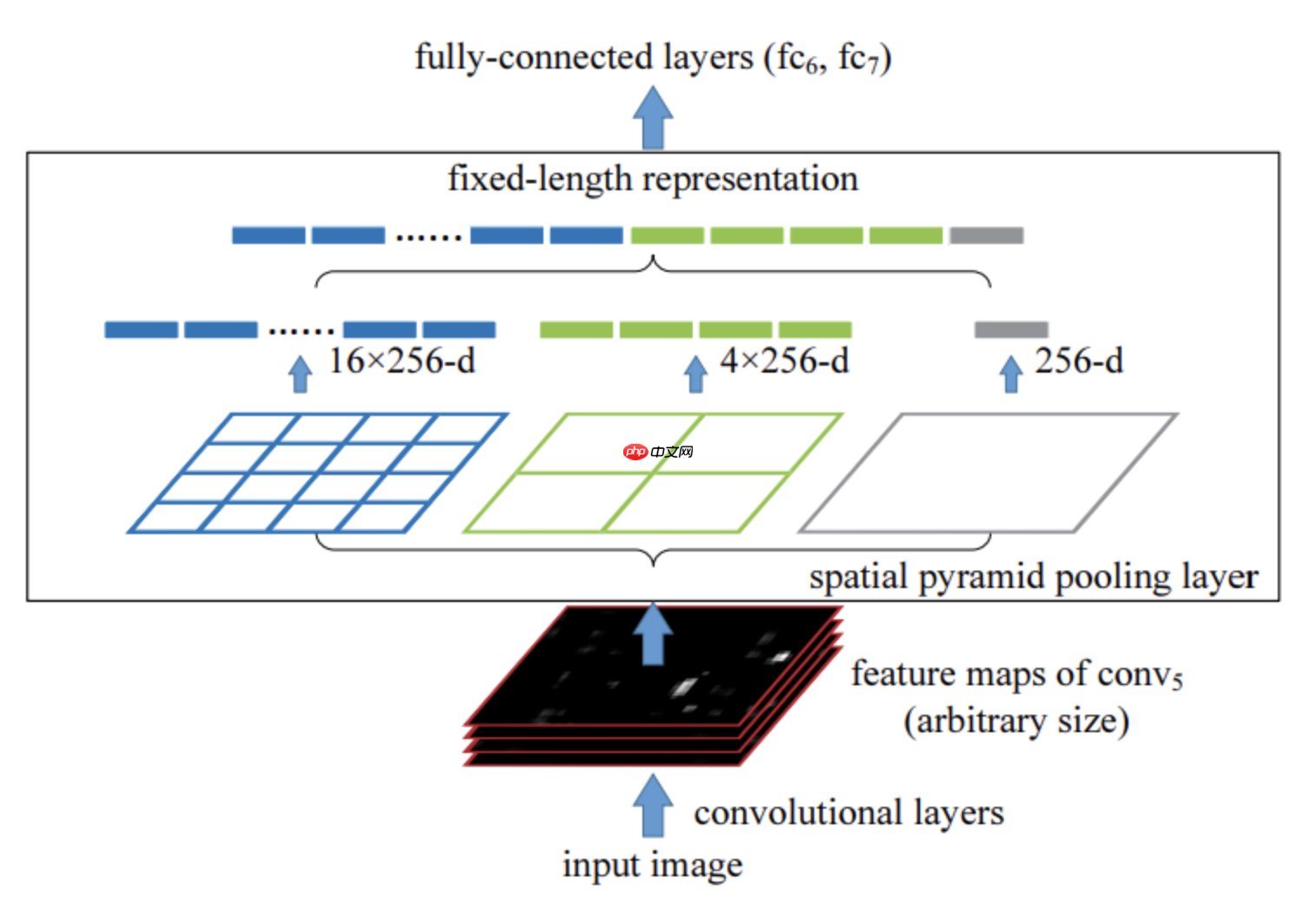
- 代码复现
import mathimport paddleimport paddle.nn as nnimport functoolsimport numpy as npimport paddle.nn.functional as Fdef spatial_pyramid_pool(previous_conv, num_sample, previous_conv_size, out_pool_size):
'''
previous_conv: a tensor vector of previous convolution layer
num_sample: an int number of image in the batch
previous_conv_size: an int vector [height, width] of the matrix features size of previous convolution layer
out_pool_size: a int vector of expected output size of max pooling layer
returns: a tensor vector with shape [1 x n] is the concentration of multi-level pooling
'''
# print(previous_conv.size())
for i in range(len(out_pool_size)):
# print(previous_conv_size)
# out_pool_size[i]
h_wid = int(math.ceil(previous_conv_size[0] / out_pool_size[i]))
w_wid = int(math.ceil(previous_conv_size[1] / out_pool_size[i]))
h_pad = (h_wid*out_pool_size[i] - previous_conv_size[0] + 1)
w_pad = (w_wid*out_pool_size[i] - previous_conv_size[1] + 1)
maxpool = nn.MaxPool2D((h_wid, w_wid), stride=(h_wid, w_wid), padding=(h_pad, w_pad))
x = maxpool(previous_conv) if(i == 0): # spp = x.reshape(num_sample,-1)
spp = paddle.reshape(x, [num_sample,-1]) else:
spp = paddle.concat([spp,paddle.reshape(x, [num_sample,-1])], 1) return spp4.2 R-Drop论文复现
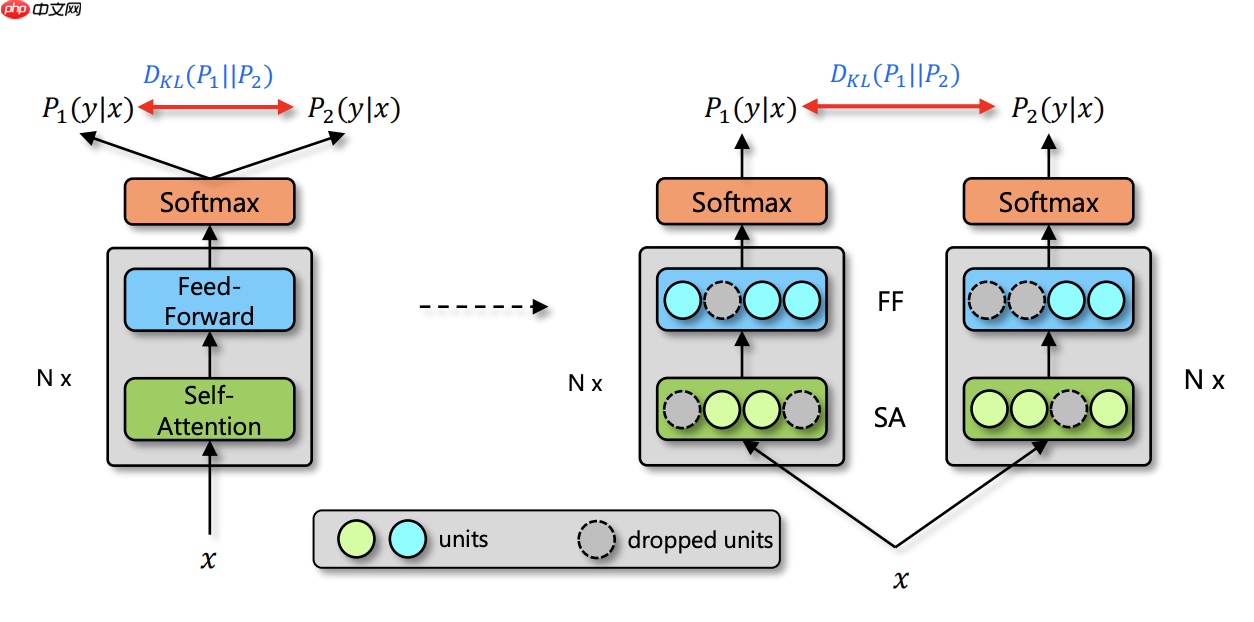
由于深度神经网络非常容易过拟合,因此 Dropout 方法采用了随机丢弃每层的部分神经元,以此来避免在训练过程中的过拟合问题。正是因为每次随机丢弃部分神经元,导致每次丢弃后产生的子模型都不一样,所以 Dropout 的操作一定程度上使得训练后的模型是一种多个子模型的组合约束。基于 Dropout 的这种特殊方式对网络带来的随机性,研究员们提出了 R-Drop 来进一步对(子模型)网络的输出预测进行了正则约束。论文通过实验得出一种改进的正则化方法R-dropout,简单来说,它通过使用若干次(论文中使用了两次)dropout,定义新的损失函数。实验结果表明,尽管结构非常简单,但是却能很好的防止模型过拟合,进一步提高模型的正确率。模型主体如下图所示。
- 代码复现
import paddle.nn.functional as F
# define your task model, which outputs the classifier logits
model = TaskModel()def compute_kl_loss(self, p, q, pad_mask=None):
p_loss = F.kl_div(F.log_softmax(p, axis=-1), F.softmax(q, axis=-1), reduction='none')
q_loss = F.kl_div(F.log_softmax(q, axis=-1), F.softmax(p, axis=-1), reduction='none')
# pad_mask is for seq-level tasks if pad_mask is not None:
p_loss.masked_fill_(pad_mask, 0.)
q_loss.masked_fill_(pad_mask, 0.)
# You can choose whether to use function "sum" and "mean" depending on your task
p_loss = p_loss.sum()
q_loss = q_loss.sum()
loss = (p_loss + q_loss) / 2
return loss
# keep dropout and forward twice
logits = model(x)
logits2 = model(x)
# cross entropy loss for classifier
ce_loss = 0.5 * (cross_entropy_loss(logits, label) + cross_entropy_loss(logits2, label))
kl_loss = compute_kl_loss(logits, logits2)# 论文中对于CV任务的超参数
α = 0.6# carefully choose hyper-parameters
loss = ce_loss + α * kl_loss4.3 【动手学Paddle2.0系列】DropBlock理论与实战
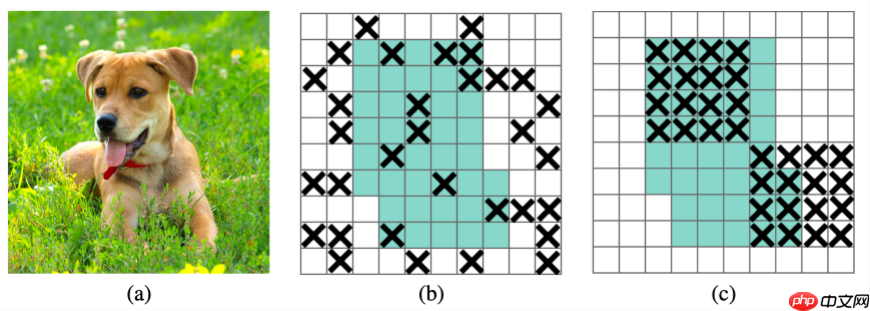
dropout被广泛地用作全连接层的正则化技术,但是对于卷积层,通常不太有效。dropout在卷积层不work的原因可能是由于卷积层的特征图中相邻位置元素在空间上共享语义信息,所以尽管某个单元被dropout掉,但与其相邻的元素依然可以保有该位置的语义信息,信息仍然可以在卷积网络中流通。因此,针对卷积网络,我们需要一种结构形式的dropout来正则化,即按块来丢弃。在本文中,我们引入DropBlock,这是一种结构化的dropout形式,它将feature map相邻区域中的单元放在一起drop掉。
dropout的主要缺点是它随机drop特征。虽然这对于全连接层是有效的,但是对于卷积层则是无效的,因为卷积层的特征在空间上是相关的。当这些特性相互关联时,即使有dropout,有关输入的信息仍然可以发送到下一层,这会导致网络overfit。
- 代码复现
class DropBlock(nn.Layer):
def __init__(self, block_size, keep_prob, name):
super(DropBlock, self).__init__()
self.block_size = block_size
self.keep_prob = keep_prob
self.name = name def forward(self, x):
if not self.training or self.keep_prob == 1: return x else:
gamma = (1. - self.keep_prob) / (self.block_size**2) for s in x.shape[2:]:
gamma *= s / (s - self.block_size + 1)
matrix = paddle.cast(paddle.rand(x.shape, x.dtype) < gamma, x.dtype)
mask_inv = F.max_pool2d(
matrix, self.block_size, stride=1, padding=self.block_size // 2)
mask = 1. - mask_inv
y = x * mask * (mask.numel() / mask.sum()) return y4.4 【动手学Paddle2.0系列】CSP实战
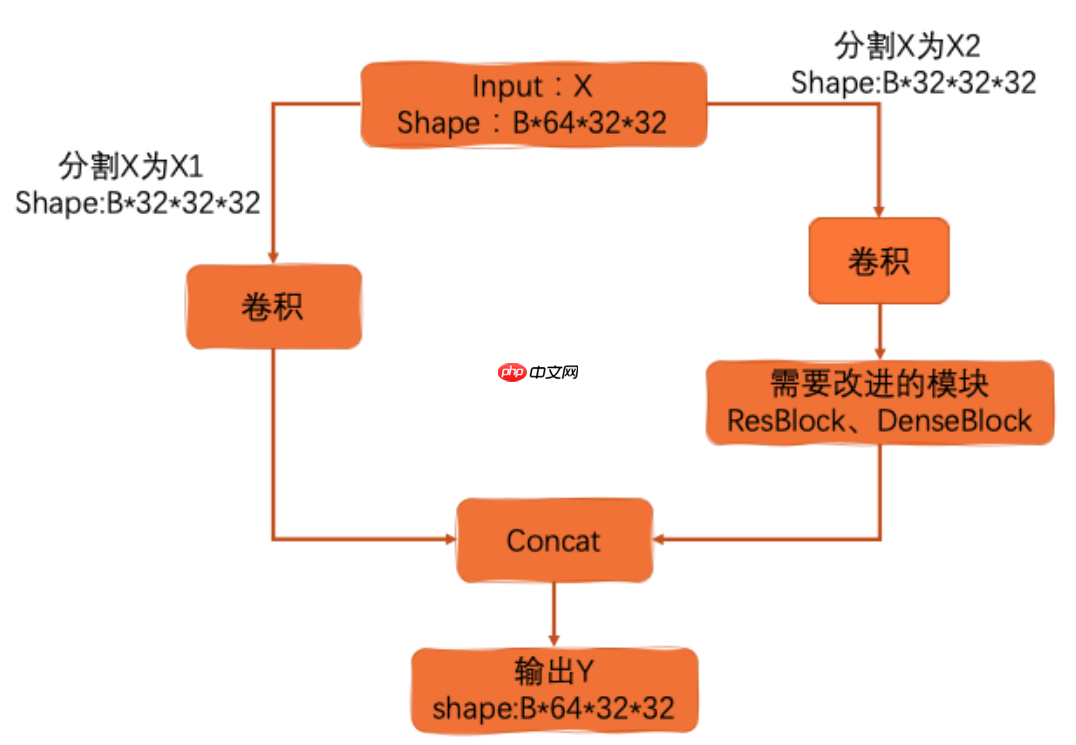
Cross Stage Partial Network(CSPNet)就是从网络结构设计的角度来解决以往工作在推理过程中需要很大计算量的问题。作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。CSPNet通过将梯度的变化从头到尾地集成到特征图中,在减少了计算量的同时可以保证准确率。CSPNet是一种处理的思想,可以和ResNet、ResNeXt和DenseNet结合。
其核心思想就是将输入切分。其目的在于提出一种新的特征融合方式(降低计算量的同时保证精度)。
5、模型训练部分
5.1 【动手学Paddle2.0系列】混合精度训练
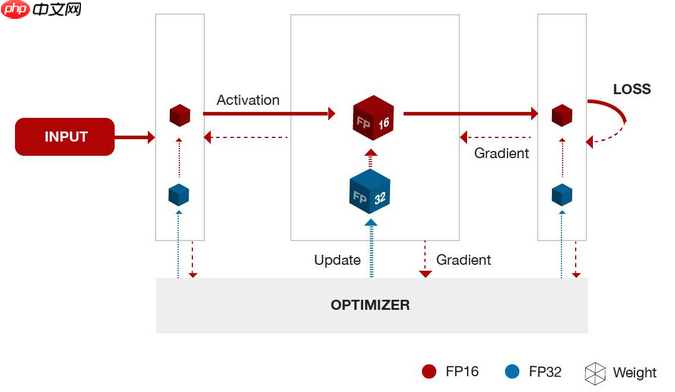
混合精度训练,指代的是单精度 float和半精度 float16 混合训练。
float16和float相比恰里,总结下来就是两个原因:内存占用更少,计算更快。
内存占用更少:这个是显然可见的,通用的模型 fp16 占用的内存只需原来的一半。memory-bandwidth 减半所带来的好处:
模型占用的内存更小,训练的时候可以用更大的batchsize。
模型训练时,通信量(特别是多卡,或者多机多卡)大幅减少,大幅减少等待时间,加快数据的流通。
计算更快:目前的不少GPU都有针对 fp16 的计算进行优化。论文指出:在近期的GPU中,半精度的计算吞吐量可以是单精度的 2-8 倍;
损失控制原理:
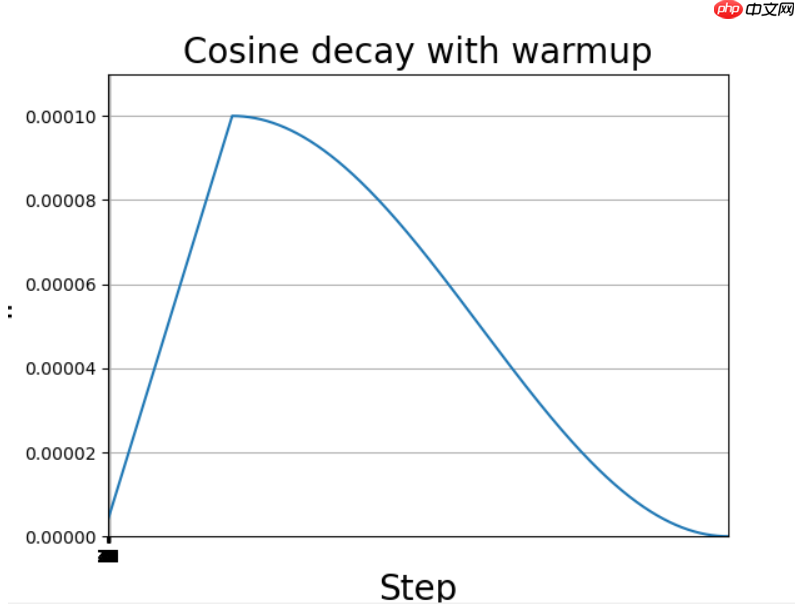
5.2 【动手学Paddle2.0系列】CosineWarmup
- Warmup
Warmup是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps(比如4个epoches,10000steps),再修改为预先设置的学习来进行训练。由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
- 余弦退火策略
当我们使用梯度下降算法来优化目标函数的时候,当越来越接近Loss值的全局最小值时,学习率应该变得更小来使得模型尽可能接近这一点,而余弦退火(Cosine annealing)可以通过余弦函数来降低学习率。余弦函数中随着x的增加余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果。
- 代码实现
from paddle.optimizer.lr import LinearWarmupfrom paddle.optimizer.lr import CosineAnnealingDecayclass Cosine(CosineAnnealingDecay):
"""
Cosine learning rate decay
lr = 0.05 * (math.cos(epoch * (math.pi / epochs)) + 1)
Args:
lr(float): initial learning rate
step_each_epoch(int): steps each epoch
epochs(int): total training epochs
"""
def __init__(self, lr, step_each_epoch, epochs, **kwargs):
super(Cosine, self).__init__(
learning_rate=lr,
T_max=step_each_epoch * epochs, )
self.update_specified = Falseclass CosineWarmup(LinearWarmup):
"""
Cosine learning rate decay with warmup
[0, warmup_epoch): linear warmup
[warmup_epoch, epochs): cosine decay
Args:
lr(float): initial learning rate
step_each_epoch(int): steps each epoch
epochs(int): total training epochs
warmup_epoch(int): epoch num of warmup
"""
def __init__(self, lr, step_each_epoch, epochs, warmup_epoch=5, **kwargs):
assert epochs > warmup_epoch, "total epoch({}) should be larger than warmup_epoch({}) in CosineWarmup.".format(
epochs, warmup_epoch)
warmup_step = warmup_epoch * step_each_epoch
start_lr = 0.0
end_lr = lr
lr_sch = Cosine(lr, step_each_epoch, epochs - warmup_epoch) super(CosineWarmup, self).__init__(
learning_rate=lr_sch,
warmup_steps=warmup_step,
start_lr=start_lr,
end_lr=end_lr)
self.update_specified = False5.3 【动手学Paddle2.0系列】模型参数EMA理论详解与实战
滑动平均(exponential moving average),或者叫做指数加权平均(exponentially weighted moving average),可以用来估计变量的局部均值,使得变量的更新与一段时间内的历史取值有关。滑动平均可以看作是变量的过去一段时间取值的均值,相比对变量直接赋值而言,滑动平均得到的值在图像上更加平缓光滑,抖动性更小,不会因为某次的异常取值而使得滑动平均值波动很大,如下图公式所示。在深度学习中,经常会使用EMA(指数移动平均)这个方法对模型的参数做平均,以求提高测试指标并增加模型鲁棒。

- 代码复现
import paddleimport numpy as npclass ExponentialMovingAverage():
def __init__(self, model, decay, thres_steps=True):
self._model = model
self._decay = decay
self._thres_steps = thres_steps
self._shadow = {}
self._backup = {} def register(self):
self._update_step = 0
for name, param in self._model.named_parameters(): if param.stop_gradient is False: # 只记录可训练参数。bn层的均值、方差的stop_gradient默认是True,所以不会记录bn层的均值、方差。
self._shadow[name] = param.numpy().copy() def update(self):
for name, param in self._model.named_parameters(): if param.stop_gradient is False: assert name in self._shadow
new_val = np.array(param.numpy().copy())
old_val = np.array(self._shadow[name])
decay = min(self._decay, (1 + self._update_step) / (10 + self._update_step)) if self._thres_steps else self._decay
new_average = decay * old_val + (1 - decay) * new_val
self._shadow[name] = new_average
self._update_step += 1
return decay def apply(self):
for name, param in self._model.named_parameters(): if param.stop_gradient is False: assert name in self._shadow
self._backup[name] = np.array(param.numpy().copy())
param.set_value(np.array(self._shadow[name])) def restore(self):
for name, param in self._model.named_parameters(): if param.stop_gradient is False: assert name in self._backup
param.set_value(self._backup[name])
self._backup = {}6、总结
作为卷积神经网络技巧不完全指北手册,介绍了一些卷积神经网络中的一些技巧,并且附上了相应的paddle实现代码,作为一份不那么完全的进阶教程来看,本指北手册应该是把模型结构各个部分的技巧讲了一下,希望能够为大家学习神经网络的道路上提供一下帮助。




























