







大家好,很高兴再次与你们见面,我是你们的朋友全栈君。
1 为什么要使用列存储? 列式存储(Columnar or column-based)与传统关系型数据库的行式存储(Row-based storage)相比,两者的主要区别在于数据的组织方式:
- 行式存储将表的数据按行顺序存储。
- 列式存储将表的数据按列顺序存储。
让我们通过一个例子来理解这一点:
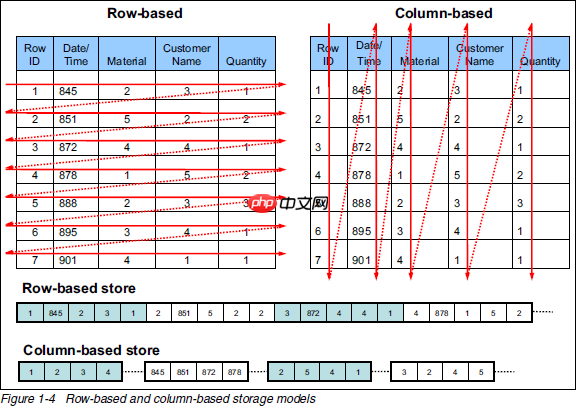
从上图可以清晰地看到,在行式存储中,一张表的所有数据都是集中在一起的,而在列式存储中,数据则是分开保存的。因此,这两种存储方式各有优缺点:
- 查询时只读取相关列
- 投影操作高效
- 任何列都可以作为索引
缺点
即使只涉及某些列,查询时也会读取所有数据
选择操作后,需要重新组装选中的列
插入和更新操作较为复杂
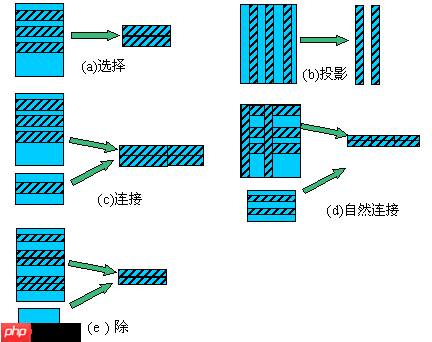
注:关系型数据库理论回顾 – 选择(Selection)和投影(Projection)

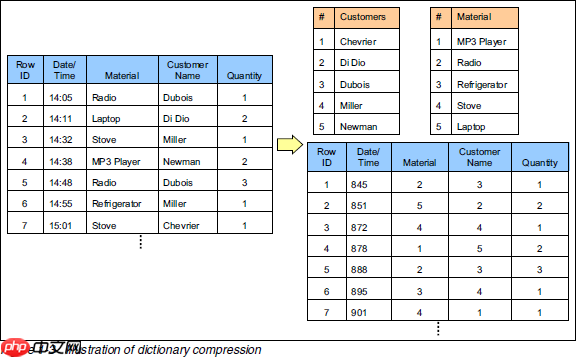
2 补充:数据压缩 之前我们略过了资料中提到的另一种技术:通过字典表压缩数据。为了方便后面的讲解,这里也顺便提一下。
下面是那张表的原始样子。通过字典表进行数据压缩后,表中的字符串都被转换成了数字。由于每个字符串在字典表中只出现一次,因此达到了压缩的目的(有点类似于规范化和非规范化)。
3 查询执行性能 下面是展示列式存储(以及数据压缩)优势的最重要的一张图,通过一条查询的执行过程进行说明:
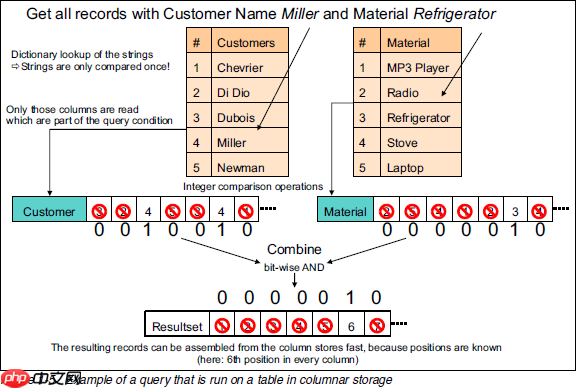
关键步骤如下:
- 在字典表中找到字符串对应的数字(只进行一次字符串比较)。
- 使用数字在列中匹配,匹配到的位置设为1。
- 对不同列的匹配结果进行位运算,得到符合所有条件的记录索引。
- 使用这些索引组装出最终的结果集。
发布者:全栈程序员栈长,转载请注明出处:https://www.php.cn/link/e735c2e2f0eda0a7eddc67a21cbebea6 原文链接:https://www.php.cn/link/c8377ad2a50fb65de28b11cfc628d75c




























