







概述
随着自动驾驶和服务机器人等新兴人工智能应用需求的不断增长,在拥挤场景中进行轨迹预测已成为近年来一个重要课题。有效建模社交互动是轨迹预测的一大挑战。过去几年中,已提出多种新颖方法。然而,这些方法是在可用数据的不同子集上进行评估的,因此难以客观比较结果。TrajNet++,一个大规模的以交互为中心的基于轨迹的基准测试,不仅包含适当的轨迹采样数据,还提供统一的广泛评估系统,用于测试收集的方法,以进行公平比较。
标注格式场景代码语言:javascript代码运行次数:0运行复制```javascript {“scene”: {“id”: 266, “p”: 254, “s”: 10238, “e”: 10358, “fps”: 2.5, “tag”: 2}}
id: 场景ID p: 行人ID s, e: 行人“p”的开始和结束帧ID fps: 帧率。tag: 轨迹类型。详细讨论如下。轨迹代码语言:javascript代码运行次数:0运行复制```javascript {“track”: {“f”: 10238, “p”: 248, “x”: 13.2, “y”: 5.85, “pred_number”: 0, “scene_id”: 123}}
f: 帧ID p: 行人ID x, y: 帧“f”中行人“p”的x和y坐标(以米为单位)。pred_number: 预测编号。这在提供多个预测而非单一预测时有用。最多允许3个预测。scene_id: 在提供场景中其他代理的预测而非仅主要行人预测时有用。
轨迹分类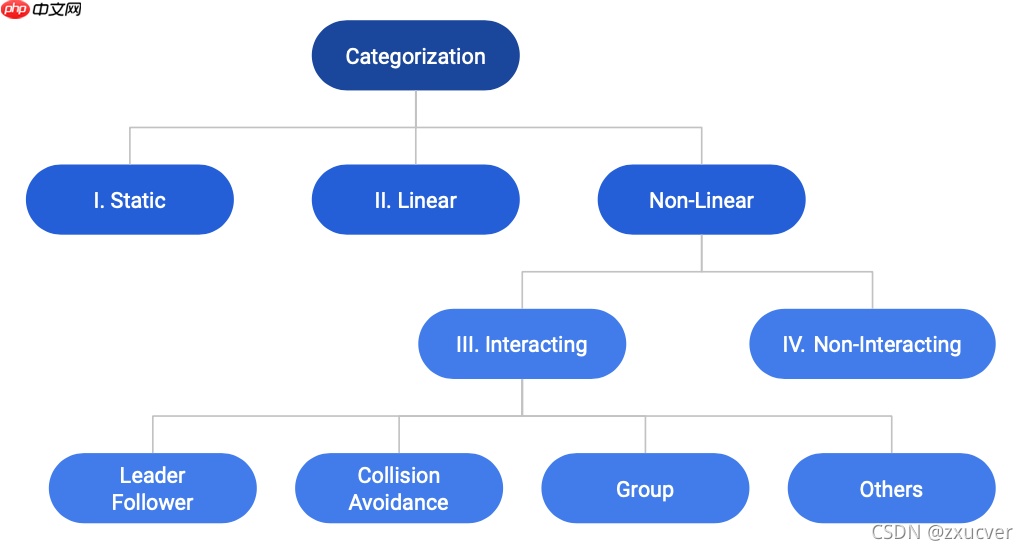
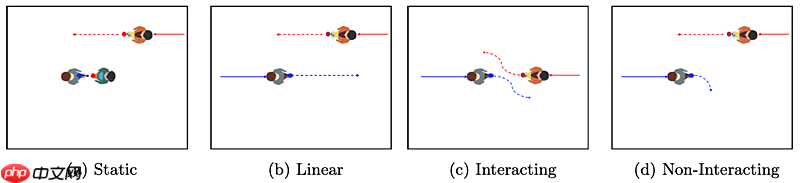
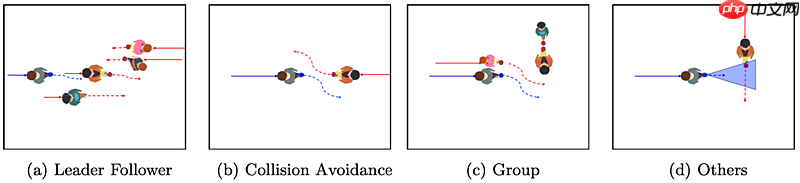 评价单模态指标:单一预测平均位移误差(ADE):在所有预测时间步长上,主行人的真实轨迹与预测轨迹之间的平均L2距离。数值越低越好。
评价单模态指标:单一预测平均位移误差(ADE):在所有预测时间步长上,主行人的真实轨迹与预测轨迹之间的平均L2距离。数值越低越好。
最终位移误差(FDE):主行人的最终真实坐标与最终预测坐标之间的L2距离。数值越低越好。
预测碰撞(Col-I):计算主行人与场景中邻近行人的碰撞百分比。使用邻近行人的模型预测来检查碰撞发生情况。数值越低越好。
真实碰撞(Col-II):计算主行人与场景中邻近行人的碰撞百分比。使用邻近行人的真实轨迹来检查碰撞发生情况。数值越低越好。

多模态指标:多重预测Topk平均位移误差(Topk_ADE):对于一个观察到的场景,给定k个输出预测,该指标计算在ADE方面最接近真实轨迹的预测的ADE。数值越低越好。在此挑战中,k=3。
Topk最终位移误差(Topk_FDE):对于一个观察到的场景,给定k个输出预测,该指标计算在ADE方面最接近真实轨迹的预测的FDE。数值越低越好。在此挑战中,k=3。
平均负对数似然(NLL):对于一个观察到的场景,给定n个输出预测,该指标计算在预测时间范围内,模型预测分布中真实轨迹的平均负对数似然。数值越高越好。在此挑战中,n=50。
参考aicrowd trajnet challengeAwesome Interaction-aware Behavior and Trajectory PredictionHuman Trajectory Forecasting in Crowds:A Deep Learning PerspectiveTrajNet++: Large-scale Trajectory Forecasting Benchmark




























